Nginx 惊群问题的原理和解决方案
惊群问题是什么?
TLDR:有一个请求过来了,把很多进程都唤醒了,但只有其中一个能最终处理。
惊群问题(thundering herd)是指多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(或者线程),但是最终却只能有一个进程(线程)获得这个时间的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群问题
对于 Nginx 而言是指当多个Nginx worker 进程同时监听同一个socket 端口,并且有新的连接进来时,所有worker 进程都会被唤醒,但最终只有一个worker 进程能够成功接收这个连接,其他进程则会返回错误并重新进入休眠状态。这种不必要的唤醒和上下文切换会导致系统资源的浪费,降低性能。
惊群问题产生原因
内核唤醒机制: 当一个事件(如新的TCP 连接)发生时,操作系统会唤醒所有在该事件上阻塞的进程。Nginx 的worker 进程在监听同一个socket 端口时,会共享这个socket,当有新连接时,所有worker 进程都会被唤醒。
accept 导致的惊群问题
当多个进程/线程调用accept监听同一个socket上时,一个新连接的到来就会导致所有阻塞在该socket上的进程/线程都被唤醒,但是最后只有一个进程/线程可以accept成功,其余的又会重新休眠,这样就产生了惊群现象。
这个问题其实在linux2.6内核版本就已经解决了,它维护了一个等待队列(队列的元素为进程),并且使用了WQ_FLAG_EXCLUSIVE 标志位来标记, 非 exclusive 元素会加在等待队列的前面,而 exclusive 元素会加在等待队列的末尾,当有新连接到来时,会遍历等待队列,并且只唤醒第一个exclusive进程
内核2.6及之后的解决流程
- 没有
WQ_FLAG_EXCLUSEVE标志置位的 exclusive 进程会加在等待队列的前面,而 exclusive 进程会加在等待队列的末尾 - 当 wake_up 被在一个等待队列上调用时, 只唤醒第一个exclusive进程(非互斥的进程由于排在队列前面也会被唤醒)就退出遍历
- 对于互斥等待的行为,比如对一个listen后的socket描述符,多线程阻塞 accept 时,系统内核只会唤醒所有正在等待此时间的队列 的第一个,队列中的其他人则继续等待下一次事件的发生,这样就避免的多个线程同时监听同一个socket描述符时的惊群问题。
阻塞在accept上的进程都是互斥的(也就是WQ_FLAG_EXCLUSIVE标志位会被置位),因此现在的linux内核调用accept时,多个进程/线程只有一个会被唤醒并建立新连接。
而nginx中处理的主要是另外一种,epoll导致的惊群问题 (确切的来说,是解决多个
epfd(epfd是指调用epoll_create获取的描述符) 共同监听同一个socket造成的惊群问题)。
epoll 导致的惊群问题
虽然accept上已经不存在惊群问题了,但是以目前的服务器架构,都不会简单的使用accept阻塞等待新的连接了,而是使用epoll等I/O多路复用机制。早期的linux,调用epoll_wait后,当有读/写事件发生时,会唤醒阻塞在epoll_wait上的所有进程/线程,造成惊群现象。不过这个问题已经被修复了,使用类似于处理accpet导致的惊群问题的方法,当有事件发生时,只会唤醒等待队列中的第一个exclusive进程来处理。不过随后就可以看到,这种方法并不能完全解决惊群问题。
这里需要区分一下两种不同的情况(这两种情况,目前linux内核都有处理的办法)。
其实也就是epoll_create和fork这两个函数调用的先后顺序问题(下面都以进程为例)。第一种情况,先调用epoll_create获取epfd,再使用fork,各进程共用同一个epfd;第二种情况,先fork,再调用epoll_create,各进程独享自己的epfd。
在fork之前创建epollfd,所有进程共用一个epoll
进程共享 epoll 情况下惊群问题触发流程:
- 主进程创建
listenfd, 创建epollfd - 主进程
fork多个子进程 - 每个子进程把
listenfd,加到epollfd中 - 当一个连接进来时,会触发epoll惊群,多个子进程的epoll同时会触发
分析:这里的epoll惊群跟accept惊群是类似的,共享一个epollfd, 加锁或标记解决。在新版本的epoll中已解决。但在内核2.6及之前是存在的。
在fork之后创建epollfd,每个进程独用一个epoll,然后监听同一个socket
进程独占 epoll 情况下惊群问题触发流程:
- 主进程创建listendfd
- 主进程创建多个子进程
- 每个子进程创建自已的
epollfd - 每个子进程把
listenfd加入到epollfd中 - 当一个连接进来时,会触发epoll惊群,多个子进程epoll同时会触发
分析:因为每个子进程的epoll是不同的epoll, 虽然listenfd是同一个,但新连接过来时, accept会触发惊群,但内核不知道该发给哪个监听进程,因为不是同一个epoll。所以这种惊群内核并没有处理。惊群还是会出现。
而nginx面对的是第二种情况,这点需要分清楚(网上有很多用第一种情况来引入nginx处理惊群问题的方法,不要被混淆了)。因为nginx的每个worker进程相互独立,拥有自己的
epfd,不过根据配置文件中的listen指令都监听了同一个端口,调用epoll_wait时,若共同监听的套接字有事件发生,就会造成每个worker进程都被唤醒。
Nginx 针对惊群问题的解决方法
ACCPET_MUTEX(应用层的解决方案)
看到 mutex 可能你就知道了,锁嘛!这也是对于高并发处理的 ”基操“ 遇事不决加锁,没错,加锁肯定能解决问题。 当请求到达,谁拿到了这个锁,谁就去处理。没拿到的就不管了。锁的问题很直接,除了慢没啥不好的,但至少很公平。
accept_mutex 实现的源码: ngx_event_accept.c#L328
值得注意的是,在支持
EPOLLEXCLUSIVE标志(Linux 4.5+)或使用reuseport选项的现代系统中,通常不需要启用accept_mutex。这些内核级别的特性本身就能在操作系统层面解决惊群问题,使得Nginx可以直接依赖底层机制,简化了配置,并可能提供更好的性能。因此,在新版本的Nginx和支持这些特性的操作系统上,accept_mutex的默认值通常是off
EPOLLEXCLUSIVE(内核层的解决方案)
EPOLLEXCLUSIVE是 2016 年 4.5+ 内核新添加的一个 epoll 的标识。它降低了多个进程/线程通过 epoll_ctl 添加共享 fd 引发的惊群概率,使得一个事件发生时,只唤醒一个正在 epoll_wait 阻塞等待唤醒的进程(而不是全部唤醒)。
在 EPOLLEXCLUSIVE 出现之前,当多个进程或线程都通过 epoll_ctl 将同一个监听套接字添加到各自的 epoll 实例中时,一旦有新的连接到来,所有这些进程/线程都会收到通知并被唤醒。这就是典型的“惊群问题”:尽管最终只有一个进程能够成功调用 accept() 来处理这个新连接,但所有被唤醒的进程都会白白消耗 CPU 资源进行不必要的上下文切换和竞争,从而降低了系统的整体效率。
EPOLLEXCLUSIVE 的引入改变了这种行为,其工作原理如下:
独占性通知: 当你使用
EPOLL_CTL_ADD操作将一个监听套接字添加到 epoll 实例时,如果同时设置了EPOLLEXCLUSIVE标志,那么当这个套接字上发生事件(例如,新的客户端连接)时,只有一个注册了EPOLLEXCLUSIVE的 epoll 实例会被内核通知到。这意味着只会唤醒一个对应的进程或线程。避免无谓竞争: 由于内核确保了每次只有一个进程被唤醒来处理事件,其他等待在同一个套接字上的进程则保持睡眠状态,从而有效地避免了多个进程同时被唤醒而导致的无谓竞争和资源浪费。
内核层面的负载均衡: 内核会智能地选择唤醒哪个 epoll 实例。虽然具体的调度策略可能因内核版本和负载情况而异(例如,早期的实现可能偏向于 LIFO 行为,即最后加入等待队列的进程优先被唤醒),但其目标始终是为了实现连接在多个工作进程间的均匀分发,而无需应用层(如 Nginx 的
accept_mutex)进行额外的协调或加锁操作。
与 accept_mutex 的比较:
Nginx 的 accept_mutex 是在应用层通过互斥锁机制来避免惊群。它需要Nginx Worker进程在用户空间进行协作:一个Worker进程获取锁后才能去监听和接受连接,其他Worker进程则等待。
而 EPOLLEXCLUSIVE 是在内核层实现的。操作系统内核直接负责将新连接的通知发送给唯一的监听者,从而从根本上消除了惊群问题。这种方式效率更高,因为它避免了用户空间互斥锁的开销和额外的上下文切换。
关键是:每次内核只唤醒一个睡眠的进程处理资源但,这个方案不是完美的解决了,它仅是降低了概率。为什么这样说呢?相比于原来全部唤醒,那肯定是好了不少,降低了冲突。但由于本质来说 socket 是共享的,当前进程处理完成的时间不确定,在后面被唤醒的进程可能会发现当前的 socket 已经被之前唤醒的进程处理掉了。
SO_REUSEPORT(内核层的解决方案)
nginx 在 1.9.1 版本加入了这个功能 Socket Sharding in NGINX Release 1.9.1 其本质是利用了 Linux 的 reuseport 的特性,使用 reuseport 内核允许多个进程 listening socket 到同一个端口上,而从内核层面做了负载均衡,每次唤醒其中一个进程。
在没有 SO_REUSEPORT 之前,通常情况下,只有一个进程能够成功地 bind()(绑定)并 listen()(监听)某个特定的 IP 地址和端口。如果多个进程想要处理同一个端口的传入连接,它们就必须通过某种机制(如 Nginx 的 accept_mutex)来协调,以避免惊群。
SO_REUSEPORT 解决了这个问题,它的工作原理如下:
允许多个进程/线程绑定到同一端口: 当你在创建套接字并调用
bind()之前设置了SO_REUSEPORT选项,那么即使这个端口已经被其他进程或线程占用了,你仍然可以成功地绑定到同一个 IP 地址和端口。这意味着你可以启动多个工作进程,每个进程都拥有自己的监听套接字,并且都监听在同一个端口上。内核层面的负载均衡: 当一个新连接(SYN 包)到达这个共享的端口时,Linux 内核会直接负责将这个连接分发给其中一个已经绑定并监听了该端口的套接字。内核通常使用一种哈希函数(基于连接的四元组,即源IP、源端口、目的IP、目的端口)来决定将连接分配给哪个套接字。
消除惊群: 由于内核直接将新连接分配给特定的监听套接字,因此只有被选中的那个套接字对应的进程或线程才会被唤醒。其他进程或线程不会收到通知,也不会被无谓地唤醒。这从根本上消除了惊群问题,因为不再是所有进程都被通知并争抢一个连接,而是只有一个进程被精准地唤醒来处理它。
提高并发能力和负载均衡: 这种机制使得服务器应用程序能够充分利用多核 CPU 的优势。每个 CPU 核心可以有一个或多个独立的 worker 进程/线程,它们各自拥有独立的监听套接字。内核的哈希分发机制确保了传入连接能够比较均匀地分布到不同的 worker 进程中,从而提高了整体的并发处理能力和负载均衡效果。
反应到 nginx 上就是,每个 worker 进程都创建独立的 listening socket,监听相同的端口,accept 时只有一个进程会获得连接。效果就和下图所示一样。
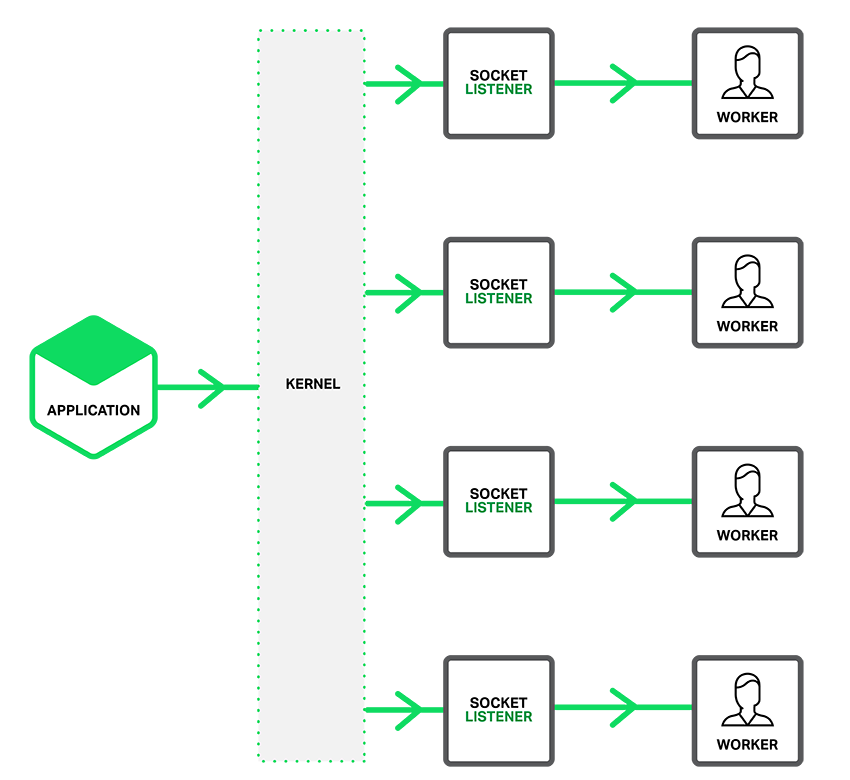
在 Nginx 中使用 SO_REUSEPORT 非常简单,只需要在 listen 指令中添加 reuseport 参数即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
events {
worker_connections 1024;
# 可以在这里关闭 accept_mutex,因为 reuseport 已经解决了惊群问题,
# Nginx 内部会智能地判断是否需要开启 accept_mutex,当检测到 reuseport 或 EPOLLEXCLUSIVE 等更优的方案时,它可能会自动禁用 accept_mutex
# accept_mutex off;
}
http {
server {
listen 80 reuseport; # 在这里添加 reuseport 参数
server_name example.com;
location / {
proxy_pass http://backend_servers;
}
}
}
当然,正所谓:完事无绝对,技术无银弹。这个方案的问题在于内核是不知道你忙还是不忙的。只会无脑的丢给你。与之前的抢锁对比,抢锁的进程一定是不忙的,现在手上的工作都已经忙不过来了,没机会去抢锁了;而这个方案可能导致,如果当前进程忙不过来了,还是会只要根据 reuseport 的负载规则轮到你了就会发送给你,所以会导致有的请求被前面慢的请求卡住了。