HTTP 发展简史
HTTP 协议的历史
超文本传输协议(HyperText Transfer Protocol,HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础。
HTTP 是万维网(World Wide Web)的基础协议。自 Tim Berners-Lee 博士和他的团队在 1989-1991 年间创造出它以来,HTTP 已经发生了太多的变化,在保持协议简单性的同时,不断扩展其灵活性。如今,HTTP 已经从一个只在实验室之间交换文件的早期协议进化到了可以传输图片,高分辨率视频和 3D 效果的现代复杂互联网协议。
发展历史
史前时期
20 世纪 60 年代,美国国防部高等研究计划署(ARPA)建立了 ARPA 网,它有四个分布在各地的节点,被认为是如今互联网的始祖。
然后在 70 年代,基于对 ARPA 网的实践和思考,研究人员发明出了著名的 TCP/IP 协议。由于具有良好的分层结构和稳定的性能,TCP/IP 协议迅速战胜其他竞争对手流行起来,并在 80 年代中期进入了 UNIX 系统内核,促使更多的计算机接入了互联网。
创世纪
1989 年,任职于欧洲核子研究中心(CERN)的蒂姆·伯纳斯 - 李(Tim Berners-Lee)发表了一篇论文,提出了在互联网上构建超链接文档系统的构想。这篇论文中他确立了三项关键技术。
- URI:即统一资源标识符,作为互联网上资源的唯一身份;
- HTML:即超文本标记语言,描述超文本文档;
- HTTP:即超文本传输协议,用来传输超文本。
这三项技术在如今的我们看来已经是稀松平常,但在当时却是了不得的大发明。基于它们,就可以把超文本系统完美地运行在互联网上,让各地的人们能够自由地共享信息,蒂姆把这个系统称为「万维网」(World Wide Web),也就是我们现在所熟知的 Web。
所以在这一年,我们的英雄 HTTP 诞生了,从此开始了它伟大的征途。
20 世纪 90 年代 初期的互联网世界非常简陋,计算机处理能力低,存储容量小,网速很慢,还是一片信息荒漠 。网络上绝大多数的资源都是纯文本,很多通信协议也都使用纯文本,所以 HTTP 的设计也不可避免地受到了时代的限制。
这一时期的 HTTP 被定义为 0.9 版,结构比较简单,为了便于服务器和客户端处理,它也采用了纯文本格式。蒂姆·伯纳斯 - 李最初设想的系统里的文档都是只读的,所以只允许用 GET 动作从服务器上获取 HTML 文档,并且在响应请求之后立即关闭连接,功能非常有限。
HTTP/0.9 虽然很简单,但它作为一个原型,充分验证了 Web 服务的可行性,而简单也正是它的优点,蕴含了进化和扩展的可能性,因为:「把简单的系统变复杂」,要比 「把复杂的系统变简单」容易得多。
早期的 HTTP/0.9 发布之初没有版本号,是后来加上去的,用于区分之后的 1.0/1.1
Web 时代
1993 年,NCSA(美国国家超级计算应用中心)开发出了 Mosaic,是第一个可以图文混排的浏览器,随后又在 1995 年开发出了服务器软件 Apache,简化了 HTTP 服务器的搭建工作。
同一时期,计算机多媒体技术也有了新的发展:1992 年发明了 JPEG 图像格式,1995 年发明了 MP3 音乐格式。
这些新软件新技术一经推出立刻就吸引了广大网民的热情,更的多的人开始使用互联网,研究 HTTP 并提出改进意见,甚至实验性地往协议里添加各种特性,从用户需求的角度促进了 HTTP 的发展。
于是在这些已有实践的基础上,经过一系列的草案,HTTP/1.0 版本在 1996 年正式发布。它在多方面增强了 0.9 版,形式上已经和我们现在的 HTTP 差别不大了,例如:
- 增加了 HEAD、POST 等新方法;
- 增加了响应状态码,标记可能的错误原因;
- 引入了协议版本号概念;
- 引入了 HTTP Header(头部)的概念,让 HTTP 处理请求和响应更加灵活;
- 传输的数据不再仅限于文本。
但 HTTP/1.0 并不是一个「标准」,只是记录已有实践和模式的一份参考文档,不具有实际的约束力,相当于一个「备忘录」。
所以 HTTP/1.0 的发布对于当时正在蓬勃发展的互联网来说并没有太大的实际意义,各方势力仍然按照自己的意图继续在市场上奋力拼杀。
HTTP/0.9 没有 RFC,1.0 的 RFC 编号是 1945
Netscape VS. IE
1995 年,网景的 Netscape Navigator 和微软的 Internet Explorer 开始了著名的「浏览器大战」,都希望在互联网上占据主导地位。

这场战争的结果你一定早就知道了,最终微软的 IE 取得了决定性的胜利,而网景则败走麦城(但后来却凭借 Mozilla Firefox 又扳回一局)。
浏览器大战的是非成败我们放在一边暂且不管,不可否认的是,它再一次极大地推动了 Web 的发展,HTTP/1.0 也在这个过程中经受了实践检验。于是在浏览器大战结束之后的 1999 年,HTTP/1.1 发布了 RFC 文档,编号为 2616,正式确立了延续十余年的传奇。
从版本号我们就可以看到,HTTP/1.1 是对 HTTP/1.0 的小幅度修正。但一个重要的区别是:它是一个正式的标准 ,而不是一份可有可无的参考文档。这意味着今后互联网上所有的浏览器、服务器、网关、代理等等,只要用到 HTTP 协议,就必须严格遵守这个标准,相当于是互联网世界的一个「立法」。
不过,说 HTTP/1.1 是小幅度修正也不太确切,它还是有很多实质性进步的。毕竟经过了多年的实战检验,比起 0.9/1.0 少了学术气,更加接地气,同时表述也更加严谨。HTTP/1.1 主要的变更点有:
- 增加了 PUT、DELETE 等新的方法;
- 增加了缓存管理和控制;
- 明确了连接管理,允许持久连接;
- 允许响应数据分块(chunked),利于传输大文件;
- 强制要求 Host 头,让互联网主机托管成为可能。
HTTP/1.1 的推出可谓是众望所归,互联网在它的保驾护航下迈开了大步,由此走上了康庄大道,开启了后续的 Web 1.0、Web 2.0 时代。现在许多的知名网站都是在这个时间点左右创立的,例如 Google、新浪、搜狐、网易、腾讯等。
不过由于 HTTP/1.1 太过庞大和复杂,所以在 2014 年又做了一次修订,原来的一个大文档被拆分成了六份较小的文档,编号为 RFC7230-RFC7235,优化了一些细节,但此外没有任何实质性的改动。
Chrome
HTTP/1.1 发布之后,整个互联网世界呈现出了爆发式的增长,度过了十多年的快乐时光,更涌现出了 Facebook、Twitter、淘宝、京东等互联网新贵。
这期间也出现了一些对 HTTP 不满的意见,主要就是连接慢,无法跟上迅猛发展的互联网,但 HTTP/1.1 标准一直「岿然不动」,无奈之下人们只好发明各式各样的小花招来缓解这些问题,比如以前常见的切图、JS 合并等网页优化手段。
终于有一天,搜索巨头 Google 忍不住了,决定揭竿而起,就像马云说的「如果银行不改变,我们就改变银行」。那么,它是怎么「造反」的呢?
Google 首先开发了自己的浏览器 Chrome,然后推出了新的 SPDY 协议,并在 Chrome 里应用于自家的服务器,如同十多年前的网景与微软一样,从实际的用户方来「倒逼」HTTP 协议的变革,这也开启了第二次的浏览器大战。
SPDY 是由 Google 开发的一种旨在提升网页加载速度和安全性的网络协议,它是 HTTP/2 的前身。它通过在 TCP 连接上实现多路复用、请求优先级划分、HTTP 头部压缩以及服务端推送等关键技术,解决了 HTTP/1.x 协议存在的性能瓶颈。
随着 HTTP/2 标准的正式发布,SPDY 的技术成果被采纳,并逐渐被浏览器淘汰,从目前的网络中退役,转而支持更先进的 HTTP/2 协议。
历史再次重演,不过这次的胜利者是 Google,Chrome 目前的全球的占有率超过了 60%。「挟用户以号令天下」,Google 借此顺势把 SPDY 推上了标准的宝座,互联网标准化组织以 SPDY 为基础开始制定新版本的 HTTP 协议,最终在 2015 年发布了 HTTP/2,RFC 编号 7540 。
HTTP/2 的制定充分考虑了现今互联网的现状:宽带、移动、不安全,在高度兼容 HTTP/1.1 的同时在性能改善方面做了很大努力,主要的特点有:
- 二进制协议,不再是纯文本;
- 可发起多个请求,废弃了 1.1 里的管道;
- 使用专用算法压缩头部,减少数据传输量;
- 允许服务器主动向客户端推送数据;
- 增强了安全性,「事实上」要求加密通信。
虽然 HTTP/2 到今天已经七岁,也衍生出了 gRPC 等新协议,但由于 HTTP/1.1 实在是太过经典和强势,目前它的普及率还比较低,大多数网站使用的仍然还是 20 多年前的 HTTP/1.1。
未来
从上个世纪 90 年代互联网开始兴起一直到现在,大部分的互联网流量传输只使用了几个网络协议。使用 IPv4 进行路由,使用 TCP 进行连接层面的流量控制,使用 SSL/TLS 协议实现传输安全,使用 DNS 进行域名解析,使用 HTTP 进行应用数据的传输。
而且近三十年来,这几个协议的发展都非常缓慢。TCP 主要是拥塞控制算法的改进,SSL/TLS 基本上停留在原地,几个小版本的改动主要是密码套件的升级,TLS1.3 是一个飞跃式的变化,但截止到今天,还没有正式发布。IPv4 虽然有一个大的进步,实现了 IPv6,DNS 也增加了一个安全的 DNSSEC,但和 IPv6 一样,部署进度较慢。
随着移动互联网快速发展以及物联网的逐步兴起,网络交互的场景越来越丰富,网络传输的内容也越来越庞大,用户对网络传输效率和 WEB 响应速度的要求也越来越高。
一方面是历史悠久使用广泛的古老协议,另外一方面用户的使用场景对传输性能的要求又越来越高。如下几个由来已久的问题和矛盾就变得越来越突出。
- 协议历史悠久导致中间设备僵化。
- 依赖于操作系统的实现导致协议本身僵化。
- 建立连接的握手延迟大。
- 队头阻塞。
在 HTTP/2 还处于草案之时,Google 又发明了一个新的协议,叫做 QUIC,而且还是相同的「套路」,继续在 Chrome 和自家服务器里试验着「玩」,依托它的庞大用户量和数据量,持续地推动 QUIC 协议成为互联网上的「既成事实」。
功夫不负有心人,当然也是因为 QUIC 确实自身素质过硬。
在 2018 年,互联网标准化组织 IETF 提议将「HTTP over QUIC」更名为 HTTP/3 并获得批准,HTTP/3 正式进入了标准化制订阶段, RFC 编号 9114.
HTTP 的各个版本
HTTP 0.9
最初版本的 HTTP 协议并没有版本号,后来它的版本号被定位在 0.9 以区分后来的版本。
HTTP/0.9 极其简单:请求由单行文本指令构成(基于文本的协议),它直接将协议的文本内容作为 TCP 负载来发送,以唯一可用方法 GET 开头,其后跟目标资源的路径(一旦连接到服务器,协议、服务器、端口号这些都不是必须的)。
HTTP 0.9 的通信流程如下:
- 客户端建立一个到服务器的 TCP 连接。
- 客户端直接在 TCP 连接上发送一行文本,这行文本就是请求内容,比如
GET /index.html。 - 服务器接收到这行文本后,解析出请求的路径,然后直接将
/index.html文件的内容作为文本,通过这个 TCP 连接发送回客户端。 - 文件内容发送完毕后,服务器会立即关闭 TCP 连接。
HTTP/0.9 的主要特点
- 极简主义: 它只支持 GET 方法,用于从服务器获取 HTML 文档。
- 无请求头: 客户端发送的请求只包含一行,即 GET 方法和请求资源的路径。例如:下文所示
- 无响应头: 服务器的响应也只包含一个 HTML 文档本身,没有状态码或任何其他元数据。
- 一次性连接: 每完成一个请求和响应,TCP 连接就会立即关闭。这意味着如果要获取多个资源(比如一个 HTML 页面和页面中的一张图片),就需要建立两次独立的 TCP 连接。
- 只支持 HTML: HTTP/0.9 只能传输 HTML 文件,无法处理图片、CSS、JavaScript 或其他类型的文件。
1
GET /mypage.html
响应也极其简单的:只包含响应文档本身。
1
2
3
<html>
这是一个非常简单的 HTML 页面
</html>
跟后来的版本不同,HTTP/0.9 的响应内容并不包含 HTTP 头。这意味着只有 HTML 文件可以传送,无法传输其他类型的文件。也没有状态码或错误代码。一旦出现问题,一个特殊的包含问题描述信息的 HTML 文件将被发回,供人们查看。
HTTP/0.9 的设计理念非常简单,因为它最初只是为了在研究机构内部传输超文本(Hypertext)而设计的。然而,随着万维网的迅速发展,这种简单的设计很快就无法满足需求。它缺乏灵活性和扩展性,无法处理除了文本以外的其他数据,也不能实现更复杂的交互。
HTTP 1.0
HTTP/1.0 是 HTTP 协议的第二个版本,于 1996 年发布,是第一个被广泛使用的 HTTP 版本。相较于简陋的 HTTP/0.9,HTTP/1.0 引入了许多重要的新特性,使其能够支持更丰富的 Web 应用。
简介
由于 HTTP/0.9 协议的应用十分有限,浏览器和服务器迅速扩展内容使其用途更广:
- 协议版本信息现在会随着每个请求发送(HTTP/1.0 被追加到了 GET 行)。
- 状态码会在响应开始时发送,使浏览器能了解请求执行成功或失败,并相应调整行为(如更新或使用本地缓存)。
- 引入了 HTTP 标头的概念,无论是对于请求还是响应,允许传输元数据,使协议变得非常灵活,更具扩展性。
- 在新 HTTP 标头的帮助下,具备了传输除纯文本 HTML 文件以外其他类型文档的能力(凭借
Content-Type标头)。
在 1991-1995 年,这些新扩展并没有被引入到标准中以促进协助工作,而仅仅作为一种尝试。服务器和浏览器添加这些新扩展功能,但出现了大量的互操作问题。直到 1996 年 11 月,为了解决这些问题,一份新文档(RFC 1945)被发表出来,用以描述如何操作实践这些新扩展功能。文档 RFC 1945 定义了 HTTP/1.0,但它是狭义的,并不是官方标准。
新特性
- 引入了请求和响应头(Header): 这是 HTTP/1.0 最大的改进。请求和响应不再是简单的文本流,而是由 头信息 和 消息体 两部分组成。
- 请求头: 包含了关于客户端、请求资源、接受内容类型等信息,例如
User-Agent(浏览器信息)、Accept(可接受的文件类型)等。 - 响应头: 则包含了关于服务器、返回内容、缓存策略等信息,例如
Content-Type(返回的内容类型)、Content-Length(内容长度)等。
- 请求头: 包含了关于客户端、请求资源、接受内容类型等信息,例如
- 支持多种请求方法: 除了
GET之外,HTTP/1.0 还引入了POST(用于向服务器提交数据,如表单)和HEAD(只获取响应头,不返回消息体)等方法。 - 支持多种文件类型: 通过
Content-Type响应头,服务器可以告诉客户端返回的是 HTML、图片、CSS、JavaScript 或其他任何类型的文件。这使得 Web 页面能够包含图片、样式表等多种资源,不再局限于纯文本。 - 引入状态码: 响应现在会包含一个三位数的 状态码,例如
200 OK(成功)、404 Not Found(找不到资源)和500 Internal Server Error(服务器内部错误),让客户端能更好地理解请求的处理结果。
HTTP 1.0 的更新请求案例
一个典型的请求看起来就像这样:
1
2
3
4
5
6
7
8
9
10
11
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
一个包含图片的页面
<IMG SRC="/myimage.gif">
</HTML>
接下来是第二个连接,请求获取图片(并具有相同的响应):
1
2
3
4
5
6
7
8
GET /myimage.gif HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:32 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/gif
(这里是图片内容)
短连接的性能问题
尽管 HTTP/1.0 带来了巨大的进步,但它仍然存在一个严重的性能瓶颈:默认是短连接。
- 每次请求都需要建立新的 TCP 连接: 客户端每发送一个请求,都需要先和服务器建立 TCP 连接,请求完成后立即关闭。这意味着如果要加载一个包含 10 张图片的网页,浏览器需要进行 11 次 TCP 连接的建立和关闭(一个 HTML 页面,10 张图片),这会消耗大量时间和资源,尤其是在网络延迟高的情况下。
- 不支持持久连接: 虽然一些浏览器和服务器通过非官方的
Connection: keep-alive 头部字段尝试实现持久连接,但这不是标准行为,兼容性也差。
为了解决这些问题,HTTP/1.1 应运而生,它正式引入了 持久连接,极大地提升了 Web 性能。
HTTP 1.1
HTTP/1.0 多种不同的实现方式在实际运用中显得有些混乱。自 1995 年开始,即 HTTP/1.0 文档发布的下一年,就开始修订 HTTP 的第一个标准化版本。在 1997 年1月,HTTP1.1 标准发布,就在 HTTP/1.0 发布的几个月后, 编号: RFC 2068 , 在同年6月修订为 RFC 2616。
简介
HTTP/1.1 消除了大量歧义内容并引入了多项改进:
- 连接可以复用,节省了多次打开 TCP 连接加载网页文档资源的时间。
- 增加管线化技术,允许在第一个应答被完全发送之前就发送第二个请求,以降低通信延迟。
- 支持响应分块,允许服务器在不知道整个响应内容长度的情况下,将响应分块发送。
- 支持断点续传, 允许客户端只请求资源的一部分,而不是整个文件。
- 引入额外的缓存控制机制。
- 引入内容协商机制,包括语言、编码、类型等。并允许客户端和服务器之间约定以最合适的内容进行交换。
- 凭借
Host标头,能够使不同域名配置在同一个 IP 地址的服务器上。
一个典型的请求流程,所有请求都通过一个连接实现,看起来就像这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
GET /zh-CN/docs/Glossary/CORS-safelisted_request_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.9
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/zh-CN/docs/Glossary/CORS-safelisted_request_header
200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 20 Jul 2016 10:55:30 GMT
Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache
Transfer-Encoding: chunked
Vary: Cookie, Accept-Encoding
(content)
GET /static/img/header-background.png HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/zh-CN/docs/Glossary/CORS-safelisted_request_header
200 OK
Age: 9578461
Cache-Control: public, max-age=315360000
Connection: keep-alive
Content-Length: 3077
Content-Type: image/png
Date: Thu, 31 Mar 2016 13:34:46 GMT
Last-Modified: Wed, 21 Oct 2015 18:27:50 GMT
Server: Apache
(image content of 3077 bytes)
新特性
持久连接 (Persistent Connections)
这是 HTTP/1.1 最重要的改进。它允许客户端和服务器在发送多个请求和响应时,可以重用同一个 TCP 连接。
默认情况下,连接在一次请求-响应交换后不会立即关闭,而是保持打开状态。客户端可以继续在这个连接上发送下一个请求,服务器也会继续在这个连接上发送响应。
HTTP1.1增加Connection字段,通过设置Keep-Alive保持HTTP连接不断卡。避免每次客户端与服务器请求都要重复建立释放建立TCP连接。提高了网络的利用率。
如果客户端想关闭HTTP连接,可以在请求头中携带Connection:false来告知服务器关闭请求。
解决了 HTTP/1.0 中频繁建立和关闭连接所带来的性能开销。这极大地减少了网络延迟和服务器负担,提高了网页加载速度。
管道化 (Pipelining)
HTTP/1.1 允许客户端在发送一个请求后,不需要等待服务器的响应就可以发送下一个请求。类似与非阻塞调用
客户端可以像流水线一样,连续发送多个请求。服务器也会按顺序处理这些请求,并按顺序返回响应。
进一步减少了网络往返时间(RTT),特别是在高延迟的网络环境下。
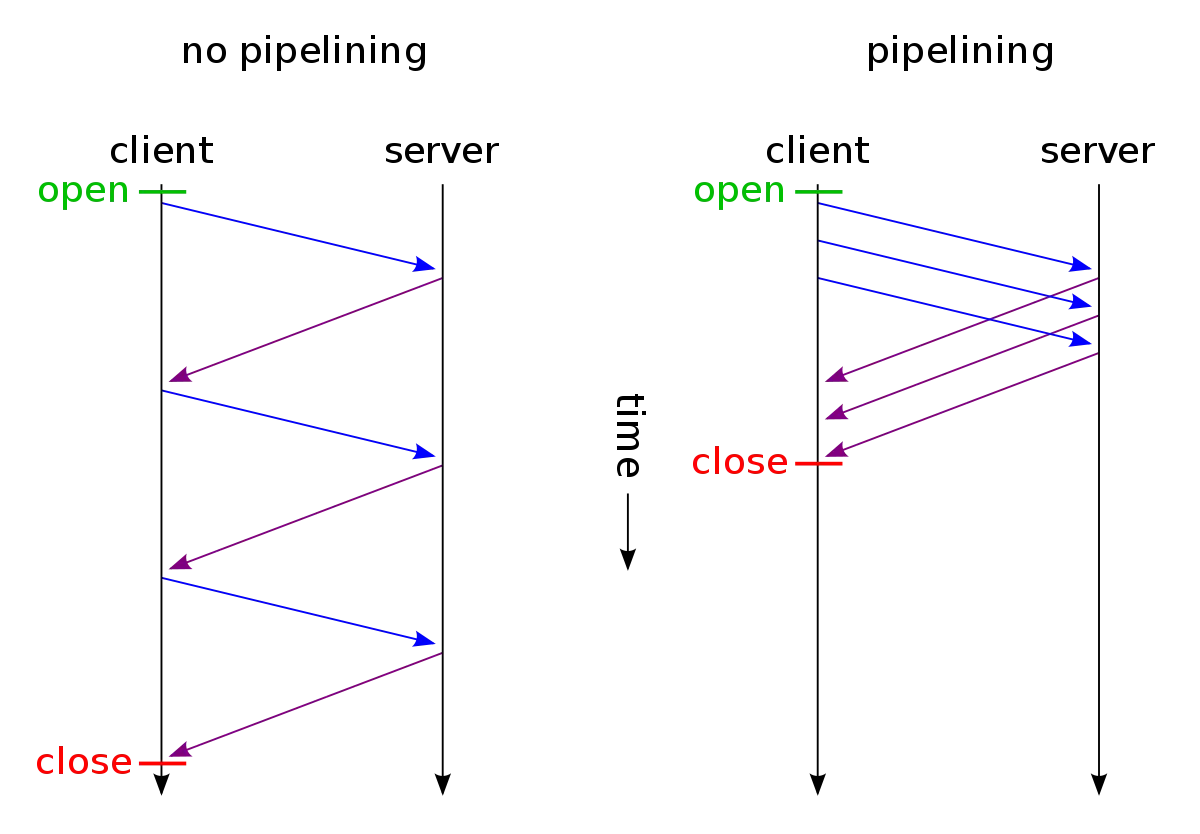
管道化的工作原理
管道化依赖于 HTTP/1.1 的持久连接。它的基本流程如下:
- 建立连接:客户端和服务器之间首先建立一个 TCP 持久连接。
- 批量发送请求:客户端在连接上连续发送多个 HTTP 请求,而不需要等待服务器对每个请求的响应。
- 按序处理响应:服务器接收到这些请求后,会按照它们到达的顺序来处理,并同样按照这个顺序来发送响应。
服务器必须按照客户端请求的先后顺序依次回送相应的结果,以保证客户端能够区分出每次请求的响应内容。
然而,由于服务器必须按顺序返回响应,它会造成队头阻塞,一个慢响应会阻塞所有后续的响应。
由于这个严重的设计缺陷,现代浏览器几乎都默认关闭了 HTTP/1.1 的管道化功能。
分块传输编码(Chunked Transfer Encoding)
在 HTTP/1.1 中,有一个非常重要的功能叫做分块传输编码(Chunked Transfer Encoding),它允许服务器在不知道整个响应内容长度的情况下,将响应分块发送。
为什么需要分块传输?
在 HTTP/1.0 中,响应必须包含 Content-Length 头部,用来告诉客户端整个响应体的长度。这意味着服务器必须在发送响应之前,就计算出所有内容的总大小。这对于那些动态生成的内容(比如一个大型数据库查询结果、一个实时生成的报告,或者一个流媒体)来说,是极不方便,甚至是无法做到的。服务器必须将所有内容都缓冲起来,直到生成完毕,才能计算出总长度并发送。这会增加延迟和服务器的内存消耗。
分块传输编码就是为了解决这个问题而设计的。
分块传输编码的工作原理
当服务器使用分块传输时,它会在响应头中加入 Transfer-Encoding: chunked,而不是 Content-Length。
响应体会被分割成一系列的分块(chunks),每个分块由以下两部分组成:
- 分块大小:一个十六进制的数字,表示当前分块的长度。
- 分块数据:实际的响应数据。
每个分块都以回车换行符(CRLF)结束。
一个典型的分块传输响应如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
4 <-- 第一个分块的大小(4个字节)
Wiki <-- 第一个分块的数据
5 <-- 第二个分块的大小(5个字节)
pedia <-- 第二个分块的数据
e <-- 第三个分块的大小(14个字节,十六进制的 e)
in
chunks. <-- 第三个分块的数据
0 <-- 最后一个分块的大小,为 0
<CRLF> <-- 最后以一个空行表示结束
断点续传 (Range Requests)
HTTP/1.1 引入了 Range 头部字段,允许客户端只请求资源的一部分,而不是整个文件。
客户端可以在请求中指定要获取的字节范围,服务器会返回该范围的数据,并使用 206 Partial Content 状态码。
方便了超大文件的下载,支持下载管理器、视频播放器等应用,可以在网络中断后从断点处恢复下载。
例如,一个客户端请求一个 10MB 的文件,但只想从第 5MB 开始下载:
1
2
3
GET /bigfile.zip HTTP/1.1
Host: example.com
Range: bytes=5242880-
服务器接收到请求后,会返回一个 206 Partial Content 状态码,并在响应体中只包含请求的那部分数据。如果客户端需要多段数据,也可以在 Range 字段中指定多个范围。
缓存控制 (Cache Control)
HTTP/1.1 提供了更精细的缓存控制机制,让开发者能够更好地管理浏览器缓存。
新增字段: 引入了 Cache-Control 头部字段,提供了比 Expires 更灵活的缓存策略,例如 max-age(缓存最大有效时间)、no-cache(不直接使用缓存,需重新验证)、no-store(不缓存任何内容)。
优化了客户端与服务器之间的数据传输,减少不必要的数据下载,提高了访问速度。
内容协商(Content Negotiation)
HTTP/1.1 中的内容协商(Content Negotiation)机制,是一种允许客户端和服务器就某个资源的最佳表示形式达成一致的机制。简单来说,它让服务器可以根据客户端的偏好,返回最适合其需求的资源版本。
为什么需要内容协商?
同一个资源,例如一篇新闻文章,可能存在多种形式:
- 多种语言:中文版、英文版、法文版。
- 多种编码:GZIP 压缩版、普通文本版。
- 多种媒体类型:HTML 文档、JSON 数据、XML 数据。
客户端(例如浏览器)可能更倾向于接收某些特定形式的内容。例如,一个位于法国的用户,其浏览器可能默认希望接收法文内容, 如果服务器能够理解并满足这种偏好,就能提供更好的用户体验。
内容协商正是为了解决这个问题而设计的,它避免了服务器为每种语言或格式都创建单独的 URL。
内容协商的工作方式
内容协商主要通过 HTTP 请求头和响应头来实现,客户端通过请求头告诉服务器它的偏好,服务器则根据这些偏好来决定返回哪个版本的资源。
以下是几个主要的内容协商请求头:
Accept:用于指定客户端可以接受的媒体类型。比如Accept: text/html, application/xhtml+xml, application/xml;q=0.9, */*;q=0.8。这里的q值表示“质量因子”,值越大表示偏好程度越高。Accept-Language:用于指定客户端可以接受的语言。比如Accept-Language: fr-CH, fr;q=0.9, en;q=0.8, de;q=0.7, *;q=0.5,表示偏好瑞士法语、法语、英语、德语,最后是其他所有语言。Accept-Encoding:用于指定客户端可以接受的内容编码方式,通常是压缩算法。比如Accept-Encoding: gzip, deflate, br。Accept-Charset:用于指定客户端可以接受的字符集。
内容协商的过程
- 客户端请求:浏览器发送请求到服务器,并在请求头中带上它的偏好(如 Accept-Language: zh-CN,en;q=0.9)。
- 服务器处理:服务器收到请求后,会检查这些请求头,并根据其内部的算法(比如根据文件的可用语言版本)来决定返回哪个版本的资源。
- 服务器响应:服务器返回最佳匹配的资源,并在响应头中包含 Content-Type 和 Content-Language 等头信息,明确告诉客户端它返回的是什么类型和语言的内容。
内容协商的两种类型
- 服务端驱动的内容协商(Server-driven Negotiation):这是最常见的方式,所有决策都在服务器端完成。客户端发送请求,服务器根据请求头自动选择并返回最合适的资源。
- 代理驱动的内容协商(Agent-driven Negotiation):这种方式比较少见。当服务器无法确定最佳版本时,它会返回一个 300 Multiple Choices 状态码,并在响应体中列出所有可用的资源版本及其对应的 URL,让客户端自己选择。
主机头 (Host Header)
在 HTTP/1.0 中,一个 IP 地址只能对应一个域名。但随着虚拟主机的普及,一台服务器可能托管多个域名。HTTP/1.1 引入了强制性的 Host 头部字段,客户端必须在请求中包含它。
客户端通过 Host 头部告诉服务器它要访问哪个域名。
解决了服务器在一台机器上托管多个网站的问题,使得虚拟主机成为可能。
问题场景:一个 IP,多个网站
想象一下,你是一家小型网络服务提供商,拥有一台强大的服务器和一个公网 IP 地址。现在你有两个客户,客户 A 有个网站叫
www.websiteA.com,客户 B 有个网站叫www.websiteB.com。你希望在同一台服务器上托管这两个网站。在 HTTP/1.0 时代,这是很难做到的。当一个请求到达你的服务器时,它只能看到请求来自哪个 IP 地址,但它不知道这个请求是要访问
www.websiteA.com还是www.websiteB.com。这就像是你的办公室只有一个门牌号,但里面有两家公司,你不知道来访者是要找哪一家。
HTTP/1.1 引入了强制性的 Host 头部字段,解决了这个问题。
当客户端(比如浏览器)请求一个网页时,它会:
首先通过 DNS 解析域名(比如 www.websiteA.com)得到服务器的 IP 地址。
然后,它向这个 IP 地址发送 HTTP 请求。
最关键的是,它在请求头中明确地加上一个 Host 字段,告诉服务器它想要访问的是哪个域名。
假设 www.websiteA.com 和 www.websiteB.com 都指向了你服务器的 IP 地址 1.2.3.4。
1
2
3
4
5
GET /index.html HTTP/1.1
Host: www.websiteA.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Accept: text/html
Connection: keep-alive
当你的服务器接收到这个请求后,它会检查 Host 头部。因为 Host 的值是 www.websiteA.com,服务器就知道该去处理和返回客户 A 网站的 /index.html 文件。
Host 头部机制的引入,让虚拟主机(Virtual Hosting)成为可能。一台服务器、一个 IP 地址,可以托管成百上千个不同的网站。服务器不再仅仅依赖于 IP 地址来识别请求的目标,而是通过 Host 头部来区分不同的域名。这极大地提高了网络资源的使用效率,是现代 Web 服务器架构的基础。
设计缺陷
队头阻塞
在 HTTP/1.1 中,队头阻塞主要发生在两种情况下:
- 管道化(Pipelining)中的队头阻塞
- 多个连接的队头阻塞
管道化中的队头阻塞
这是 HTTP/1.1 管道化机制固有的设计缺陷。
服务器必须按请求到达的顺序来处理和返回响应。如果第一个请求(队头)因为某些原因(如服务器处理慢、文件过大)延迟了,那么后面的所有请求,即使服务器已经处理完毕,也必须等待第一个响应发送完毕后,才能依次发送
举个例子:
你发送了三个请求:
- 请求 A: 获取一个巨大的图片文件
- 请求 B: 获取一个小的 CSS 文件
- 请求 C: 获取一个小的 JavaScript 文件
服务器可能很快就处理完了 B 和 C 的请求,但由于 A 的响应需要很长时间才能传输完毕,B 和 C 的响应必须排队等待,导致了不必要的延迟。
多个连接的队头阻塞
由于管道化的缺陷,现代浏览器通常会避免使用它。作为替代,它们会为每个域名开启多个并行的 TCP 连接(通常为 6 个)。但这同样会带来一种变相的队头阻塞。
如果一个网页需要加载的资源数量超过了浏览器的连接限制(例如,需要 10 个资源,但只能同时开启 6 个连接),那么剩下的 4 个请求就必须等待前面的资源请求完成后才能开始。在一个TCP连接中如果包含多个资源请求, 它仍将按照顺序请求, 这会延迟页面加载,尤其是在网络带宽有限的情况下。
HTTP 1.1 中的多个连接和 1.0 中独立TCP连接区别?
当浏览器为了绕开 HTTP/1.1 管道化的缺陷,而采取“为每个域名开启多个并行的持久连接”时,它实际上是在复制 HTTP/1.0 的并行模式,但使用了 HTTP/1.1 的长连接特性。
- 相似之处(HTTP/1.0 的并行模式):浏览器依然是并行地发送多个请求,每个请求都使用一个独立的连接。这解决了单个连接上的队头阻塞问题。
- 不同之处(HTTP/1.1 的长连接):这些并行连接是持久的。它们不会在请求完成后立即关闭,而是保持开放,用于后续的请求
这不是完全退化为 HTTP/1.0 的独立连接模式,而是一种混合模式:它保留了 HTTP/1.1 长连接的优势(避免了频繁的三次握手和四次挥手),但又回到了 HTTP/1.0 的并行连接思想,通过牺牲单连接的效率来换取整体的并行度。
TCP 层的队头阻塞
值得一提的是,HTTP/2 虽然解决了应用层的队头阻塞,但TCP 协议本身仍然存在队头阻塞。如果一个 TCP 数据包丢失,那么所有后续的数据包,即使已经到达,也必须等待丢失的那个数据包重传并被正确接收后,才能被应用层读取。HTTP/3 协议通过切换到底层传输协议 QUIC (基于 UDP) 来解决这个问题,实现了更高层面的无序传输,从而从根本上解决了队头阻塞的困扰。
连接数量的限制
为了缓解前文提到的队头阻塞,浏览器通常会为每个域名开启多个并发的持久连接(通常为 6 个)。
但是这通常也会有以下影响:
- 资源消耗:这会导致客户端和服务器端都需要维护大量的 TCP 连接,增加了系统的资源开销。
- 队头阻塞的变相存在:虽然多个连接可以并行处理请求,但如果一个页面需要加载的资源超过了浏览器的连接限制,那么超出的请求依然需要等待,形成了另一种形式的“队头阻塞”。
- TCP 慢启动:每个新开启的 TCP 连接都需要经历 TCP 慢启动阶段,这意味着连接的吞吐量从零开始逐渐增加,无法立即达到最佳性能。
顺序请求
在 HTTP/1.1 中,请求和响应必须是一一对应的,并且是严格按顺序传输的。一个请求必须在收到上一个响应后才能发送(在非管道化模式下)。即使使用管道化,服务器也必须按请求的顺序返回响应。
影响:这种严格的顺序性导致了无法实现真正的异步传输。例如,一个客户端同时向服务器请求 A 和 B 两个资源,如果服务器先准备好了 B,它也必须等待 A 准备好后,才能按顺序将 A 和 B 一起返回。这浪费了服务器的计算资源和网络带宽。
冗余的报文头
HTTP/1.1 是一个纯文本协议。每个请求和响应都包含大量的头部信息(如 User-Agent、Cookie、Accept 等)。在同一个持久连接上,如果连续发送多个请求,这些头部信息几乎是完全重复的。
影响:这种重复的文本数据增加了网络传输的负担,尤其是在移动网络等带宽受限的环境中。虽然 HTTP/1.1 的持久连接避免了 TCP 握手的开销,但重复发送这些冗长的头部信息依然浪费了大量带宽。
HTTP 2.0
这些年来,网页愈渐变得的复杂,甚至演变成了独有的应用,可见媒体的播放量,增进交互的脚本大小也增加了许多:更多的数据通过 HTTP 请求被传输。HTTP/1.1 链接需要请求以正确的顺序发送,理论上可以用一些并行的链接(尤其是 5 到 8 个),带来的成本和复杂性堪忧。比如,HTTP 管线化(pipelining)就成为了 Web 开发的负担。为此,在 2010 年早期,谷歌通过实践了一个实验性的 SPDY 协议。这种在客户端和服务器端交换数据的替代方案引起了在浏览器和服务器上工作的开发人员的兴趣。明确了响应数量的增加和解决复杂的数据传输,SPDY 成为了 HTTP/2 协议的基础。
在 2015 年 5 月正式标准化后(RFC 编号 7540),HTTP/2 取得了极大的成功,在 2022 年 1 月达到峰值,占所有网站的 46.9%(见这些统计数据)。高流量的站点最迅速的普及,在数据传输上节省了可观的成本和支出。
这种迅速的普及率很可能是因为 HTTP2 不需要站点和应用做出改变:使用 HTTP/1.1 和 HTTP/2 对他们来说是透明的。拥有一个最新的服务器和新点的浏览器进行交互就足够了。只有一小部分群体需要做出改变,而且随着陈旧的浏览器和服务器的更新,而不需 Web 开发者做什么,用的人自然就增加了。
新特性
HTTP/2 在 HTTP/1.1 有几处基本的不同:
- HTTP/2 是二进制协议而不是文本协议。不再可读,也不可无障碍的手动创建,改善的优化技术现在可被实施。
- 这是一个多路复用协议。并行的请求能在同一个链接中处理,移除了 HTTP/1.x 中顺序和阻塞的约束。
- 压缩了标头。因为标头在一系列请求中常常是相似的,其移除了重复和传输重复数据的成本。
- 其允许服务器在客户端缓存中填充数据,通过一个叫服务器推送的机制来提前请求。
消息-流-帧 概念
HTTP/2 将所有通信内容(包括请求和响应)都分解成更小的帧(Frames)通过流(Stream)来传输。
- 消息(Message): 一个消息(Message)是指一个完整的请求或响应。一个消息由一个或多个帧组成。
- 流(Stream): 在 HTTP/2 中,一个流(Stream)是一个独立的、双向的二进制字节流(或者说是一个虚拟通道, 但是这个通道只会传输对应唯一的一个请求-响应对的消息的帧),可以承载一个 HTTP/2 消息。每个流都有一个唯一的数字标识符。
- 帧(Frame): 帧是 HTTP/2 协议中最小的通信单位。每个帧都包含一个标准化的 9 字节头部,其中包含了最重要的信息,比如:
- 长度:帧的负载大小。
- 类型:帧的类型(如
HEADERS、DATA)。 - 标志(Flags):用于控制帧的特定行为。
- 流 ID(Stream ID):表明这个帧属于哪个流。这是实现多路复用的关键。
消息(Message) vs. 帧(Frame) vs. 流(Stream)
在 HTTP/2 中,这三个概念构成了一个层次结构:
- 消息(Message):这是最高层的概念,代表一个完整的逻辑请求或响应。它由一个或多个帧组成,并且与一个特定的流相关联。一个 HTTP/1.1 请求/响应在 HTTP/2 中对应的就是一个消息。
- 流(Stream):这是一个虚拟的、双向的通信通道,用于承载一个完整的消息。每个流都有一个唯一的 ID, 同一组的请求和响应共享流, 同时每个请求-响应对独占一个流。
- 帧(Frame):这是最底层的概念,是 HTTP/2 协议中最小的通信单位。一个帧包含了特定类型的数据(如 HEADERS、DATA)和一个流 ID,用来标识它属于哪个流。
既然流和请求-响应对是1对1关系,为什么还需要“消息”这个概念呢?原因在于:
- 概念上的清晰和兼容性:HTTP/2 协议设计时,一个主要目标是保持与 HTTP/1.1 协议的语义兼容性。HTTP/1.1 中的一个请求或响应(例如,一个 GET 请求或一个 200 OK 响应)就是一个完整的“消息”。HTTP/2 保留了“消息”这个概念,使得开发者和上层应用可以继续用熟悉的方式思考和处理 HTTP 请求和响应,而无需关心底层的二进制分帧细节。
- 数据结构上的抽象:一个完整的 HTTP 请求(消息)通常包含头部和消息体。在 HTTP/2 中,这被分解为不同类型的帧,例如
HEADERS帧和DATA帧。HEADERS 帧包含请求的元数据,DATA 帧包含请求的实际数据。这两个不同类型的帧都属于同一个流,但它们共同构成了一个完整的请求消息。 - 简化编程接口:对于开发者来说,直接处理底层帧(
HEADERS帧、DATA帧等)会非常复杂。HTTP/2 协议的库和框架会提供更高级的接口,让开发者可以像处理一个完整的“消息”一样来处理请求和响应。底层库负责将这个消息分解成帧,并通过流发送出去,并在接收端将帧重新组装成完整的消息。
总结:
- 一个完整的
请求(请求-响应对)独占一个流 - 一个完整的
请求(请求-响应对)包含请求和响应两条消息 - 每个
消息对应一个或多个帧 - 一个
流只能传输对应请求-响应对的消息的帧
二进制分帧(Binary Framing)
在 HTTP/2 中,二进制分帧(Binary Framing)是协议最底层、也是最根本性的改变。它为 HTTP/2 带来所有其他高级特性(如多路复用、
为什么需要二进制分帧?
HTTP/2.0 以前的 HTTP/1.1, HTTP/1.0, HTTP/0.9 是一个基于文本的协议,它的请求和响应都是由明文组成的。这种设计简单直观,但效率很低。
- 解析困难:服务器需要通过查找换行符来解析请求头和请求体,这不仅耗时,还容易出错。
- 不紧凑:明文传输会带来额外的空间开销。
- 无法实现高级功能:基于文本的传输方式很难在同一个连接上实现并发处理,因为无法区分不同请求的数据块。
为了解决这些问题,HTTP/2 彻底抛弃了文本协议,转而使用二进制协议。
二进制分帧下的一个请求-响应的例子
当你使用 HTTP/2 请求一个网页时,实际的传输过程是这样的:
- 客户端请求:
- 客户端创建一个新的流(例如,流 ID 为 1)。
- 它将请求头信息(如方法、路径、Host 等)封装到
HEADERS帧中,并在这个帧的头部标记流 ID 为 1。 - 如果请求有请求体(如 POST 请求),它会将请求体封装到 DATA 帧中,同样标记流 ID 为 1。
- 客户端将这些帧发送给服务器。
- 服务器响应:
- 服务器接收到这些帧后,根据流 ID 1 将它们重新组装成一个完整的请求。
- 服务器处理请求后,将响应头封装到
HEADERS帧中(流 ID 1),将响应体封装到 DATA 帧中(流 ID 1),然后发送回客户端。
多路复用(Multiplexing)
这是 HTTP/2 最重要的特性。它彻底解决了 HTTP/1.1 中的队头阻塞问题。
工作原理:HTTP/2 允许在单个 TCP 连接上同时发送和接收多个请求和响应。每个请求和响应都被分解成独立的、可以无序传输的“帧”(Frame),这些帧通过流(Stream)来区分。服务器和客户端可以交错发送和接收属于不同流的帧,最终在另一端将这些帧重新组装成完整的消息。
优点:消除了 HTTP/1.1 中因单个连接的队头阻塞和多连接带来的额外开销。一个连接就能完成所有资源的加载,大大提高了页面加载速度。
多路复用下的有序性保证
HTTP/2 的帧本身没有序号,它将乱序重排的重任交给了底层的 TCP 协议。HTTP/2 利用 TCP 的可靠性和有序性,实现了应用层的多路复用,从而有效解决了 HTTP/1.1 的队头阻塞问题,而不会引入自己的乱序重排复杂性。
HTTP/2 将多个不同流的、有序的帧交错地放入 TCP,然后通过 TCP 的有序性来保证这些帧到达对端时,仍然是按照发送时的顺序排列。接收端再根据帧的流 ID 将它们分离,从而重新获得每一组有序的帧。
我们可以用扑克牌类比来更精确地解释这个过程:
扑克牌类比 假设你有两副扑克牌:
一副红桃牌(流 ID 1):红桃 A, 2, 3, 4…
一副黑桃牌(流 ID 3):黑桃 A, 2, 3, 4…
这些牌本身都是有序的。
发送方(HTTP/2 客户端):
它不会先发送所有红桃,再发送所有黑桃。相反,它会像一个高超的洗牌手一样,将两副牌交错地合并在一起,形成一个混合的序列,比如:
红桃 A -> 黑桃 A -> 红桃 2 -> 红桃 3 -> 黑桃 2 -> 红桃 4...这个混合的序列就是 HTTP/2 将不同流的帧交错在一起,通过一个 TCP 连接发送出去的字节流。
传输(TCP 协议):
TCP 就像一个可靠的快递服务。它确保你发送的这个混合序列的扑克牌,会以完全相同的顺序到达收件人手里。即使中间有几张牌(数据包)丢失了,TCP 也会负责重新发送,直到所有牌都按正确的顺序到达。
接收方(HTTP/2 服务器):
服务器收到这个混合的扑克牌序列后,它会根据每张牌的花色(流 ID),将它们重新分离。
红桃 A -> 红桃 2 -> 红桃 3 -> 红桃 4...黑桃 A -> 黑桃 2 -> 黑桃 3 -> 黑桃 4...最终,服务器得到了两副完整的、各自有序的扑克牌。
这个类比概括了 HTTP/2 多路复用的工作原理:
- 扑克牌花色 = 流 ID,用来区分不同的请求。
- 单张扑克牌 = 帧,是最小的传输单位。
- 牌的顺序 = TCP 的有序传输,保证了帧的顺序。
- “洗牌” = HTTP/2 的多路复用,实现了帧的交错传输。
HTTP/2 巧妙地利用了 TCP 的有序性,将不同流的帧混合传输,然后在接收端根据流 ID 再进行分离,从而在一个连接上实现了多个请求的并行处理,彻底解决了 HTTP/1.1 的队头阻塞问题。
头部压缩(Header Compression)
HTTP/2 中的头部压缩(Header Compression)是一项重要的性能优化特性,它通过压缩请求和响应中的头部信息,大幅减少了数据传输量。
为什么需要头部压缩?
在 HTTP/1.1 协议中,请求和响应的头部是纯文本形式,并且每次请求都会重复发送大量冗余信息,比如 User-Agent、Host、Accept 和 Cookie 等。
考虑一下这样的场景:
- 你访问一个网页,浏览器需要请求 50 个小文件(图片、CSS、JS)。
- 每个请求的头部信息可能都有几百字节甚至上千字节。
- 这 50 个请求的头部加起来,传输量可能远大于实际的资源内容。
这种重复和冗长的头部信息浪费了宝贵的带宽,特别是在移动网络或高延迟环境中,成为了一个显著的性能瓶颈。
HPACK 压缩算法
为了解决这个问题,HTTP/2 引入了 HPACK 压缩算法,它专门用于对 HTTP 头部进行高效压缩。HPACK 的核心思想是用索引来代替重复的字符串。它主要通过以下三种方式实现压缩
静态字典(Static Table) HPACK 预先定义了一个包含 61 个常用头部字段和值的静态字典。例如,GET 方法、:status: 200 和 content-length 等。在传输时,如果头部字段在静态字典中,只需发送一个索引值即可,而无需发送完整的字符串。
动态字典(Dynamic Table)
客户端和服务器在每次请求-响应后,都会动态更新一个各自维护的动态字典。
如果某个头部字段在静态字典中不存在,但在这个动态字典中存在,也只需发送一个索引值。
如果一个头部是新出现的,它会被添加到动态字典中。后续如果再次出现这个头部,就可以用索引值来代替。
这种机制尤其适用于那些在一个会话中频繁出现的自定义头部字段,例如 Cookie。只要在第一次发送时传递完整的头部信息,之后就可以只用一个索引来代表它。
霍夫曼编码(Huffman Coding)
对于那些既不在静态字典,也不在动态字典中的新头部值,HPACK 会使用霍夫曼编码对其进行压缩,以进一步减少传输的字节数。
服务器推送(Server Push)
服务器推送(Server Push)允许服务器在客户端明确请求之前,主动将资源推送给客户端。
为什么需要服务器推送?
在传统的 HTTP/1.1 模式下,浏览器加载一个网页通常需要经过一系列的请求-响应循环。
- 浏览器请求 index.html。
- 服务器返回 index.html。
- 浏览器解析 HTML,发现需要 style.css 和 script.js。
- 浏览器再发起两个独立的请求,分别获取 style.css 和 script.js。
- 服务器响应这两个请求。
这个过程会产生额外的网络往返时间(RTT)。浏览器需要等待解析完 HTML 才能知道需要哪些子资源,这会造成不必要的延迟,尤其是在网络延迟高的情况下。
服务器推送的工作原理
服务器推送就是为了解决这种延迟而设计的。它利用 HTTP/2 的多路复用特性,让服务器可以在一个 TCP 连接上,同时处理多个请求和推送。
当浏览器请求 index.html 时,服务器会做以下事情:
- 服务器在发送 index.html 的响应之前,或者在发送响应的过程中,主动向客户端推送 style.css 和 script.js。
- 这些推送的资源会在一个新的流(Stream)中发送,与 index.html 的响应流并行传输。
- 客户端接收到这些推送的资源后,会把它们缓存起来。当浏览器解析 HTML,发现需要这些资源时,可以直接从缓存中获取,而无需再次发送请求。
服务器推送的优点:
- 减少网络延迟(RTT):它消除了客户端发现资源后,再发出请求的等待时间。资源在客户端需要时就已经准备就绪。
- 提高页面加载速度:对于那些有许多小文件(如 CSS、JS、图片)的网页,服务器推送能显著减少加载时间。
潜在的缺点:
- 缓存问题:如果客户端已经有了某个资源的缓存,服务器仍然推送它,就会造成带宽浪费。因此,服务器在推送前需要检查客户端的缓存状态。
- 滥用问题:如果服务器推送了客户端不需要的资源,反而会浪费客户端的流量和带宽。
HTTP 2 的服务器推送和 WebSocket 这种消息推送的区别
HTTP/2 的服务器推送是预测性的。它必须由一个客户端的初始请求触发,并且推送的内容是客户端接下来可能会需要的资源(例如,一个网页依赖的 CSS、JavaScript 文件等)。推送的本质是服务器代替客户端发起 GET 请求,来避免额外的网络延迟。
HTTP/2 服务器推送的限制:
- 单向性:推送是服务器到客户端的单向行为,客户端不能对推送的内容进行回复。
- 依赖请求:服务器推送无法脱离客户端的任何请求而单独发生。它是一种对请求的优化,而不是一种独立的通信机制。
- 无状态:服务器无法主动识别某个用户处于在线状态,并向其推送数据。它只能响应特定请求,然后进行推送。
WebSocket这种消息推送是实时的、双向的,且独立于任何 HTTP 请求。它的核心是客户端和服务器之间建立一个持久连接,服务器可以随时向这个连接发送数据
设计缺陷
尽管 HTTP/2 在性能上取得了巨大进步,但它仍然存在一个设计上的重大缺陷,这个缺陷并非源于 HTTP/2 本身,而是来自于它所依赖的底层协议——TCP。
TCP 的队头阻塞(Head-of-Line Blocking)
HTTP/2 解决了应用层的队头阻塞问题。它通过多路复用,允许在单个 TCP 连接上并行处理多个 HTTP 请求。然而,它无法解决 TCP 协议自身的队头阻塞问题。
TCP 协议为了保证数据的可靠性和有序性,会给发送的每个数据包(Segment)分配一个序号。接收方必须按照序号的顺序来处理这些数据包。如果中间有一个数据包丢失,那么所有后续到达的数据包,即使它们是完整的,也必须等待这个丢失的包被重传并成功接收后,才能被上交给 HTTP/2 协议栈。
举个例子:
假设你在一个 HTTP/2 连接上同时下载三张图片,这三张图片被分解成无数个小的数据包,通过一个 TCP 连接发送。
- 图片 A 的数据包 10 丢失了。
- 图片 B 和 图片 C 的数据包 11、12、13… 已经顺利到达。
在这种情况下,TCP 协议会暂停所有数据的处理,直到数据包 10 被重传并到达。这意味着,即使后面的数据包是属于不同的图片,并且已经准备就绪,它们也必须等待。 上个世纪 90 年代互联网开始兴起一直到现在,大部分的互联网流量传输只使用了几个网络协议。使用 IPv4 进行路由,使用 TCP 进行连接层面的流量控制,使用 SSL/TLS 协议实现传输安全,使用 DNS 进行域名解析,使用 HTTP 这个底层的阻塞会影响到所有在同一个 TCP 连接上运行的 HTTP/2 流,因为它们都依赖于这个单一的、有序的 TCP 数据流。
HTTP 3.0 (QUIC)
Quic 全称 quick udp internet connection,“快速 UDP 互联网连接”,(和英文 quick 谐音,简称“快”)是由 google 提出的使用 udp 进行多路并发传输的协议, RFC 编号 9114。
Quic 相比现在广泛应用的 http2+tcp+tls 协议有如下优势:
- 减少了 TCP 三次握手及 TLS 握手时间。
- 改进的拥塞控制。
- 避免队头阻塞的多路复用。
- 连接迁移。
- 前向冗余纠错。
历史背景
中间设备的僵化
可能是 TCP 协议使用得太久,也非常可靠。所以我们很多中间设备,包括防火墙、NAT 网关,整流器等出现了一些约定俗成的动作。
比如有些防火墙只允许通过 80 和 443,不放通其他端口。NAT 网关在转换网络地址时重写传输层的头部,有可能导致双方无法使用新的传输格式。整流器和中间代理有时候出于安全的需要,会删除一些它们不认识的选项字段。
TCP 协议本来是支持端口、选项及特性的增加和修改。但是由于 TCP 协议和知名端口及选项使用的历史太悠久,中间设备已经依赖于这些潜规则,所以对这些内容的修改很容易遭到中间环节的干扰而失败。
而这些干扰,也导致很多在 TCP 协议上的优化变得小心谨慎,步履维艰。
依赖于操作系统的实现导致协议僵化
TCP 是由操作系统在内核网络栈层面实现的,应用程序只能使用,不能直接修改。虽然应用程序的更新迭代非常快速和简单。但是 TCP 的迭代却非常缓慢,原因就是操作系统升级很麻烦。
现在移动终端更加流行,但是移动端部分用户的操作系统升级依然可能滞后数年时间。PC 端的系统升级滞后得更加严重,windows xp 现在还有大量用户在使用,尽管它已经存在快 20 年。
服务端系统不依赖用户升级,但是由于操作系统升级涉及到底层软件和运行库的更新,所以也比较保守和缓慢。
这也就意味着即使 TCP 有比较好的特性更新,也很难快速推广。比如 TCP Fast Open。它虽然 2013 年就被提出了,但是 Windows 很多系统版本依然不支持它。
建立连接的握手延迟大
不管是 HTTP1.0/1.1 还是 HTTPS,HTTP2,都使用了 TCP 进行传输。HTTPS 和 HTTP2 还需要使用 TLS 协议来进行安全传输。这就出现了两个握手延迟:
- TCP 三次握手导致的 TCP 连接建立的延迟。
- TLS 完全握手需要至少 2 个 RTT 才能建立,简化握手需要 1 个 RTT 的握手延迟。
对于很多短连接场景,这样的握手延迟影响很大,且无法消除。
TCP队头阻塞
队头阻塞主要是 TCP 协议的可靠性机制引入的。TCP 使用序列号来标识数据的顺序,数据必须按照顺序处理,如果前面的数据丢失,后面的数据就算到达了也不会通知应用层来处理。
另外 TLS 协议层面也有一个队头阻塞,因为 TLS 协议都是按照 record 来处理数据的,如果一个 record 中丢失了数据,也会导致整个 record 无法正确处理。
概括来讲,TCP 和 TLS1.2 之前的协议存在着结构性的问题,如果继续在现有的 TCP、TLS 协议之上实现一个全新的应用层协议,依赖于操作系统、中间设备还有用户的支持。部署成本非常高,阻力非常大。
所以 QUIC 协议选择了 UDP,因为 UDP 本身没有连接的概念,不需要三次握手,优化了连接建立的握手延迟,同时在应用程序层面实现了 TCP 的可靠性,TLS 的安全性和 HTTP2 的并发性,只需要用户端和服务端的应用程序支持 QUIC 协议,完全避开了操作系统和中间设备的限制。
QUIC 的优点
更快的连接建立
QUIC 的另一个优势是它能更快地建立连接。
- TCP:传统的 TCP 连接需要经过“三次握手”,如果还要使用 TLS 加密,还需要额外的 TLS 握手,通常需要 2-3 个网络往返时间(RTT)。
- QUIC:QUIC 将握手和加密集成在一起。在首次连接时,它只需要一个 RTT 就能完成连接和 TLS 握手。如果客户端和服务器之前有过连接,它甚至可以实现零 RTT 握手(0-RTT),几乎可以立即发送应用数据。
连接迁移
QUIC 连接不受 IP 或端口变更的影响。
- TCP:如果用户的 IP 地址改变了(比如从 Wi-Fi 切换到移动网络),TCP 连接会中断,需要重新建立。
- QUIC:QUIC 使用一个 64 位的连接 ID 来标识连接,而不是传统的 IP 地址和端口号。这意味着即使 IP 地址和端口变了,连接 ID 依然不变,连接可以无缝迁移,而无需重新建立。这对于移动设备来说非常重要。
独立的数据流
在 QUIC 中,每个数据流都被视为一个完全独立的实体。
- TCP/HTTP/2:所有 HTTP/2 流都必须共享同一个 TCP 连接,所有数据包都混杂在一起。如果一个数据包(比如属于流 A)丢失,TCP 协议栈会停止处理后续所有的数据,直到这个丢失的包被重传。
- QUIC/HTTP/3:QUIC 协议将每个流都视为独立的。如果流 A 的一个数据包丢失,QUIC 只会暂停流 A 的传输,并请求重传该数据包。与此同时,流 B、流 C 等其他数据流完全不会受到影响,可以继续正常传输
这就像一个多车道的高速公路(QUIC),每辆车(数据流)都在自己的车道上行驶,一辆车出了事故(丢包)只会影响它自己的车道,而不会堵塞所有车道。相比之下,TCP 更像是一条单车道,前面一辆车出事,后面所有车都得停下来。
QUIC 设计内容
更快的连接建立
0RTT 建连可以说是 QUIC 相比 HTTP2 最大的性能优势。那什么是 0RTT 建连呢?这里面有两层含义。
- 传输层 0RTT 就能建立连接。
- 加密层 0RTT 就能建立加密连接。
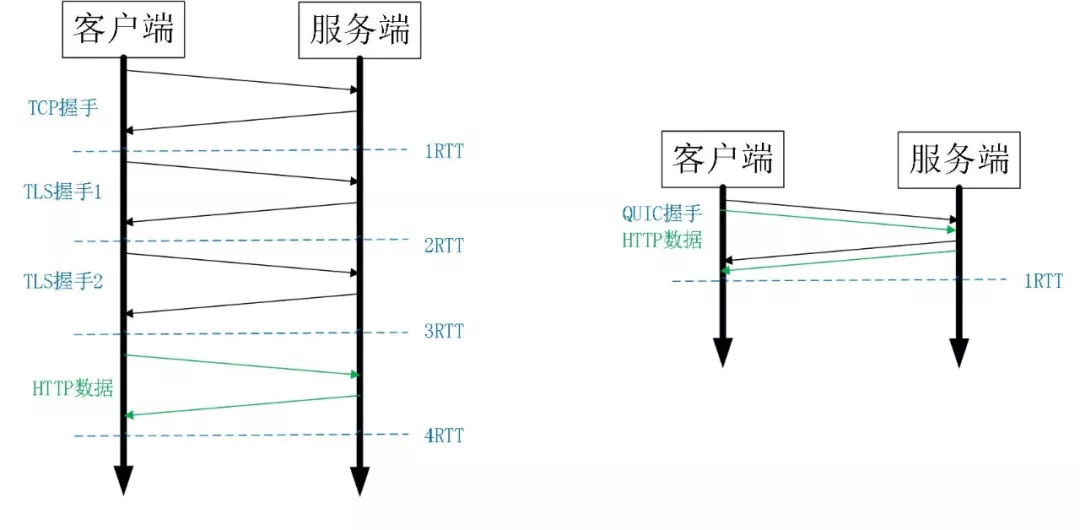
比如上图左边是 HTTPS 的一次完全握手的建连过程,需要 3 个 RTT。就算是 Session Resumption,也需要至少 2 个 RTT。
对于一个小请求(用户数据量较小)而言,传输数据只需要 1 个 RTT,但是光建连就花掉了 3 个 RTT,这是非常不划算的,这里建连包括两个过程:TCP 建连需要 1 个 RTT,TLS 建连需要 2 个 RTT。RTT:Round Trip Time,数据包在网络上一个来回的时间。
为什么需要两个过程?可恶就可恶在这个地方,TCP 和 TLS 没办法合并,因为 TCP 是在内核里完成的,TLS 是在用户态。
也许有人会说把干掉内核里的 TCP,把 TCP 挪出来放到用户态,然后就可以和 TLS 一起处理了。首先,你干不掉内核里的 TCP,TCP 太古老了,全世界的服务器的 TCP 都固化在内核里了。
所以,既然干不掉 TCP,那我不用它了,我再自创一个传输层协议,放到用户态,然后再结合 TLS,这样不就可以把两个建连过程合二为一了吗?是的,这就是 QUIC。
而 QUIC 呢?由于建立在 UDP 的基础上,同时又实现了 0RTT 的安全握手,所以在大部分情况下,只需要 0 个 RTT 就能实现数据发送,在实现前向加密的基础上,并且 0RTT 的成功率相比 TLS 的 Sesison Ticket 要高很多。
QUIC 的连接建立流程
QUIC 实现 0-RTT(Zero Round-Trip Time) 建立连接的核心思想是利用 先前会话的信息,从而在第一次发送数据时就包含加密的有效载荷(payload)
QUIC 实现 0-RTT 的过程可以分为两个阶段:
首次连接(1-RTT 握手)
在客户端首次连接到 QUIC 服务器时(或者长时间没有通信过(0-RTT 过期了),需要进行一次完整的握手,这通常需要一个往返时间(1-RTT)。在这个过程中,客户端和服务器会进行以下操作:
- 协商加密参数: 客户端向服务器发送一个初始包,包含它支持的加密套件、TLS 版本和客户端的随机数。
- 服务器响应: 服务器回复一个包含加密参数、服务器证书和会话票据(Session Ticket)的包。
- 存储会话信息: 客户端接收到服务器的响应后,会验证证书并生成共享密钥。最关键的是,客户端会将服务器发送的会话票据和加密参数(例如,用于生成密钥的会话密钥)缓存起来。
这个过程完成后,客户端和服务器就建立了一个安全的连接,并且客户端保存了重用该会话所需的所有信息。
后续连接(0-RTT 握手)
当客户端再次连接到同一台 QUIC 服务器时,它会利用之前缓存的会话信息来实现 0-RTT 握手:
- 发送 0-RTT 数据: 客户端在发送的第一个数据包中,就包含了先前会话的会话票据。这个数据包不仅包含了握手信息,还包含了加密的应用层数据。
- 服务器处理: 服务器接收到这个数据包后,会根据会话票据和已知的加密参数,快速恢复会话状态,并使用正确的密钥解密数据。如果解密成功,服务器就可以立即处理客户端发送的数据,而无需等待额外的往返。
0-RTT 的潜在风险和应对措施
虽然 0-RTT 提供了极大的延迟优势,但它也存在一个潜在的安全风险:重放攻击(Replay Attack)。
攻击者可以捕获客户端发送的 0-RTT 数据包,并将其重复发送给服务器。如果服务器不加区分地处理这些数据包,就可能导致意想不到的后果。例如,如果 0-RTT 数据包含一个“购买商品”的请求,攻击者就可以通过重放这个数据包,导致服务器多次处理这个请求。
为了应对重放攻击,QUIC 采取了以下措施:
- 数据包序号: 服务器会跟踪接收到的数据包序号,拒绝重复的请求。
- 幂等操作: 许多 0-RTT 场景仅用于执行幂等(idempotent)操作,即重复执行不会产生副作用的操作,比如获取网页内容。对于非幂等操作(例如提交表> 单),则通常需要等待 1-RTT 确认。
- Nonce: QUIC 还可以使用 一次性随机数(Nonce)来防止重放攻击。
QUIC 在客户端第一次收到服务器响应时,不需要再进行一次确认来完成“三次握手”。
QUIC 的握手过程(通常是 1-RTT)是与TCP不同的。它将连接建立、协商和 TLS 加密握手合并在一起。
- 客户端发送 Initial 包: 客户端发送一个包含加密参数、版本协商和客户端随机数的初始包给服务器。
- 服务器发送 Handshake 包: 服务器收到后,发送一个包含加密参数、服务器证书和会话票据的 Handshake 包。这个包中包含的信息已经足够让客户端确认服务器身份,并生成共享密钥。
- 客户端立即发送应用数据: 客户端收到服务器的 Handshake 包后,就可以立即开始加密并发送应用层数据了。同时也会发送一个 ACK(确认应答) 包,以确认它收到了服务器的 Handshake 包。
QUIC 是将 TCP 握手中的“第三个 ACK”和它之后才发送的“第一个数据包”合并了,从而节省了一个往返时间。
连接迁移
一条 TCP 连接是由四元组标识的(源 IP,源端口,目的 IP,目的端口)。什么叫连接迁移呢?就是当其中任何一个元素发生变化时,这条连接依然维持着,能够保持业务逻辑不中断。当然这里面主要关注的是客户端的变化,因为客户端不可控并且网络环境经常发生变化,而服务端的 IP 和端口一般都是固定的。
比如大家使用手机在 WIFI 和 4G 移动网络切换时,客户端的 IP 肯定会发生变化,需要重新建立和服务端的 TCP 连接。
又比如大家使用公共 NAT 出口时,有些连接竞争时需要重新绑定端口,导致客户端的端口发生变化,同样需要重新建立 TCP 连接。
针对 TCP 的连接变化,MPTCP其实已经有了解决方案,但是由于 MPTCP 需要操作系统及网络协议栈支持,部署阻力非常大,目前并不适用。
所以从 TCP 连接的角度来讲,这个问题是无解的。
那 QUIC 是如何做到连接迁移呢?很简单,任何一条 QUIC 连接不再以 IP 及端口四元组标识,而是以一个 64 位的随机数作为 ID 来标识,这样就算 IP 或者端口发生变化时,只要 ID 不变,这条连接依然维持着,上层业务逻辑感知不到变化,不会中断,也就不需要重连。
由于这个 ID 是客户端随机产生的,并且长度有 64 位,所以冲突概率非常低。
QUIC 限制连接迁移为仅客户端可以发起,客户端负责发起所有迁移。如果客户端接收到了一个未知的服务器发来的数据包,那么客户端必须丢弃这些数据包。
如图,连接迁移过程总共需要四个步骤。
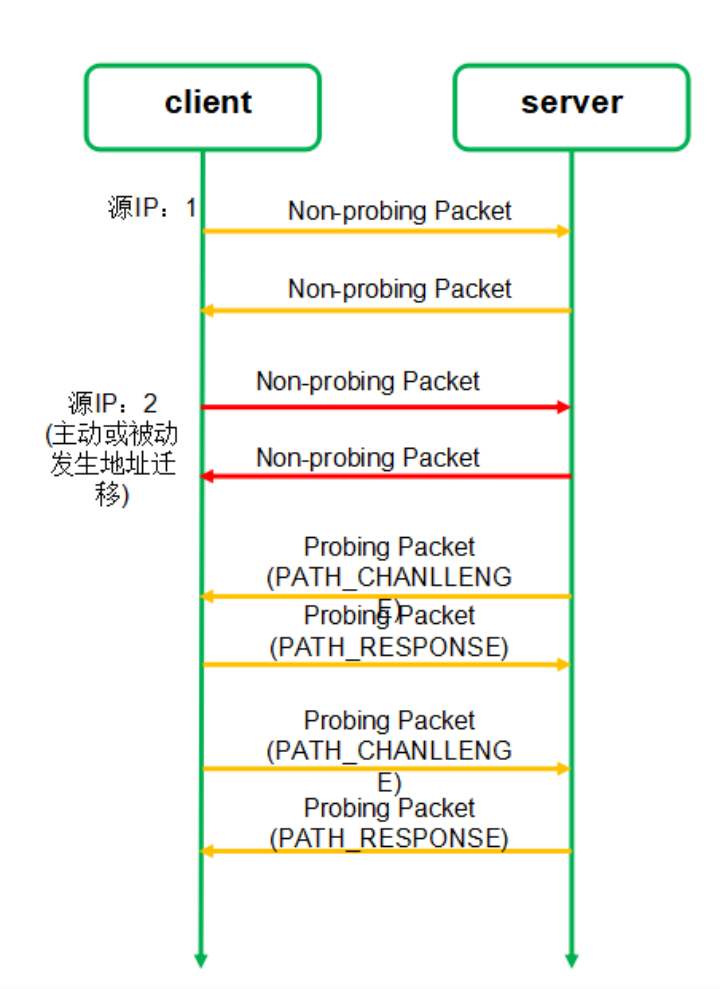
- 连接迁移之前,客户端使用 IP1 和服务端进行通信;
- 客户端 IP 变成 IP2,并且使用 IP2 发送非探测帧给服务端;
- 启动路径验证(双方都需要互相验证),通过
PATH_CHANLLENGE帧和PATH_RESPONSE帧进行验证。 - 验证通过后,使用 IP2 进行通信。
可靠传输实现
QUIC 在 UDP 之上,通过以下几个关键机制实现了可靠传输:
- Connection ID:QUIC 连接由一个 64 位的随机 ID 标识,而不是像 TCP 那样依赖 IP 地址和端口号。
- 包(Packet)和帧(Frame):QUIC 将所有数据都封装在 UDP 包中。一个 QUIC 包内部可以包含多个帧。
- 流 ID (Stream ID) + 帧类型:每个帧都带有流 ID 和类型。不同流的帧可以交错地放在同一个 UDP 包中。
- 独立的序列号:每个流都有自己独立的序列号。当发送数据时,QUIC 会在每个流上递增序列号。
- 确认 (Acknowledgement):QUIC 实现了自己的 ACK 机制,接收方收到数据后会发送 ACK 包来确认。
- 丢包重传:如果发送方在一定时间内没有收到 ACK,就会认为数据包丢失,并重新发送。这个重传过程是针对特定流进行的。
虽然 QUIC 和 HTTP/2 都使用了“流”和“帧”这两个概念,但它们的定义和作用并不完全一致
- HTTP/2 的流和帧是应用层的概念。
- QUIC 的流和帧是传输层的概念。
HTTP/2 的帧是用来封装HTTP 协议数据(例如请求头和请求体)。而 QUIC 的帧是用来封装QUIC 协议本身的数据,这些数据包括了流数据、确认信息、加密握手信息等。HTTP/3 的 HTTP 消息数据本身被封装在 QUIC 的 STREAM 帧里。
但是,在 HTTP/3 协议中,一个QUIC 流仍然是一个
HTTP 请求-响应对所独占的。这一设计是为了保证所有的 HTTP 请求可以并非执行, 不被阻塞
QUIC 和 TCP 的可靠传输有什么区别
| 协议 | QUIC | TCP |
|---|---|---|
| 基础协议 | UDP | IP |
| 数据单位 | Packet (包), Frame (帧) | Segment (段) |
| 可靠性粒度 | 基于流 (Stream) | 基于连接 (Connection) |
| 核心机制 | Connection ID + 流 ID | 序列号 (Sequence Number) |
| 队头阻塞 | 无 | 有 |
- 根本区别:可靠性的粒度
- TCP:TCP 的可靠性是针对整个连接的。它将所有数据看作一个单一的字节流。如果一个数据包丢失,整个数据流都会被阻塞,直到丢失的数据包被重传。这就是TCP 队头阻塞的根源。
- QUIC:QUIC 的可靠性是针对每个独立的流。如果一个流上的数据包丢失,只会影响该流的数据传输,而不会影响同一连接上的其他流。这是 QUIC 能够从根本上解决队头阻塞的原因。
- 序列号
- TCP:使用单一的、全局的序列号来标识连接上的所有字节。
- QUIC:使用独立的序列号来标识每个流上的字节,从而实现了流的独立性。
- 拥塞控制
- TCP:拥塞控制算法集成在操作系统内核中,更新困难。
- QUIC:拥塞控制算法在应用层实现,可以灵活地更换和部署。
- 连接管理
- TCP:依赖 IP 地址和端口号。网络切换会导致连接中断。
- QUIC:使用 Connection ID,可以实现无缝的连接迁移。
QUIC 在实现可靠传输时,巧妙地将可靠性从整个连接下放到了每个独立的流。这种设计使得一个流的丢包问题不会影响到其他流,从而解决了 TCP 队头阻塞这一历史难题,为 HTTP/3 带来了革命性的性能提升。
QUIC 的可靠传输在单个流范围上的效果,与 TCP 非常相似。你可以认为 QUIC 是在每个独立的流上,重新实现了类似于 TCP 的可靠、有序、流量控制等功能。
只是 TCP 是一种字节流协议。它将数据视为一个无边界的连续字节流,并使用序列号来追踪每个字节。
而QUIC 传输的是帧(Frame),这些帧再被封装到 UDP 包中。这种基于帧的设计让 QUIC 能够更灵活地管理数据,例如,可以将不同流的帧放在同一个 UDP 包里。
重传歧义性
QUIC 是一个可靠的协议,它使用 Packet Number 代替了 TCP 的 sequence number,并且每个 Packet Number 都严格递增,也就是说就算 Packet N 丢失了,重传的 Packet N 的 Packet Number 已经不是 N,而是一个比 N 大的值。而 TCP 呢,重传 segment 的 sequence number 和原始的 segment 的 Sequence Number 保持不变,也正是由于这个特性,引入了 Tcp 重传的歧义问题。
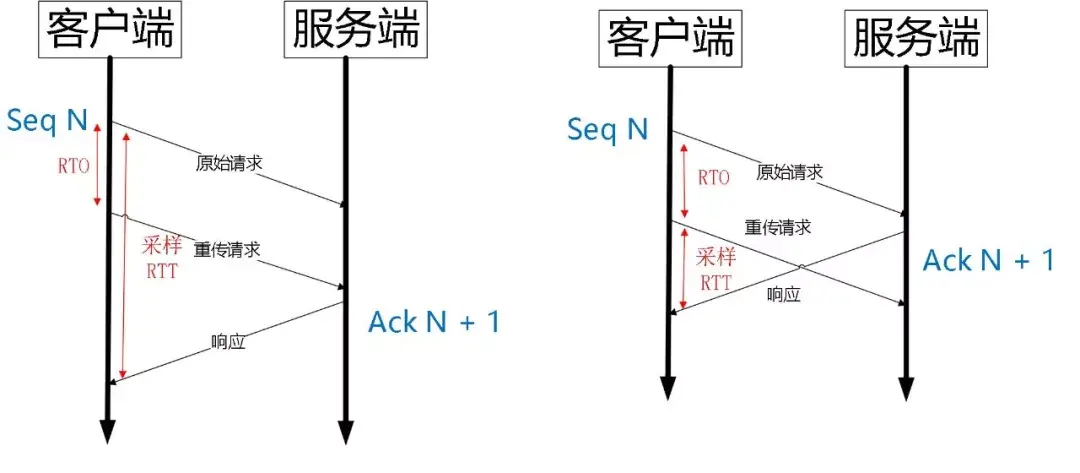
如上图所示,超时事件 RTO 发生后,客户端发起重传,然后接收到了 Ack 数据。由于序列号一样,这个 Ack 数据到底是原始请求的响应还是重传请求的响应呢?不好判断。
如果算成原始请求的响应,但实际上是重传请求的响应(上图左),会导致采样 RTT 变大。如果算成重传请求的响应,但实际上是原始请求的响应,又很容易导致采样 RTT 过小。
由于 Quic 重传的 Packet 和原始 Packet 的 Pakcet Number 是严格递增的,所以很容易就解决了这个问题。
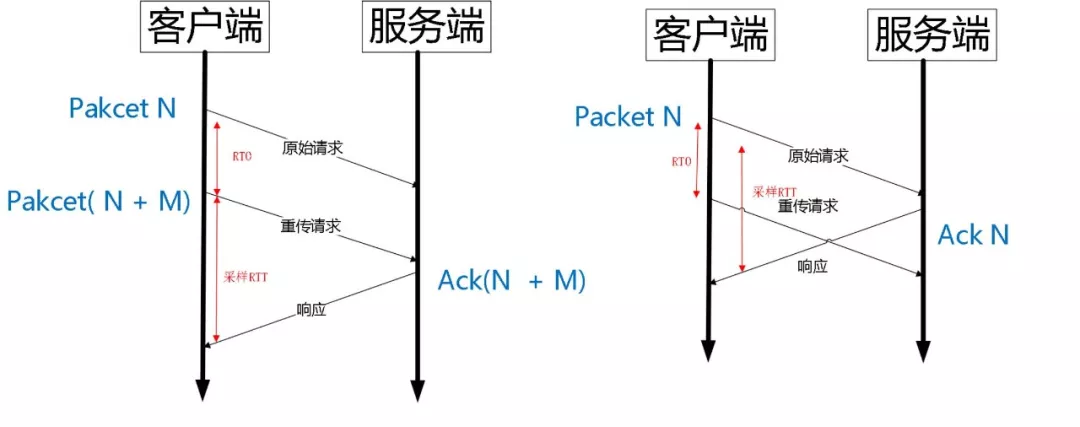
如上图所示,RTO 发生后,根据重传的 Packet Number 就能确定精确的 RTT 计算。如果 Ack 的 Packet Number 是 N+M,就根据重传请求计算采样 RTT。如果 Ack 的 Pakcet Number 是 N,就根据原始请求的时间计算采样 RTT,没有歧义性。
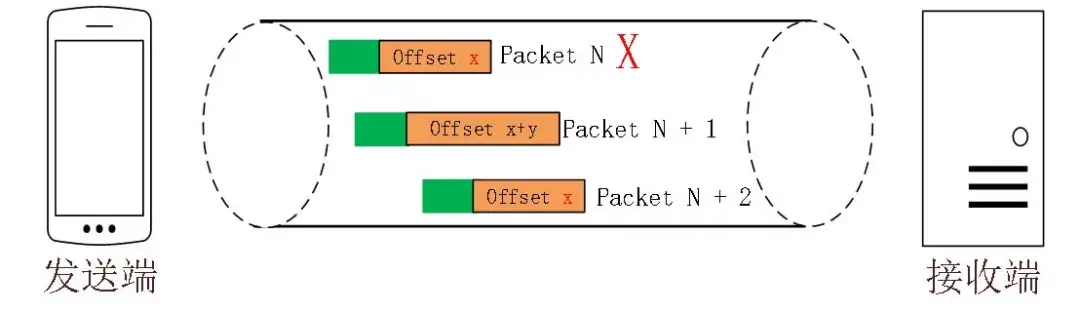
重传有序性
单纯依靠严格递增的 Packet Number 肯定是无法保证数据的顺序性和可靠性。QUIC 又引入了一个 Stream Offset 的概念。
即一个 Stream 可以经过多个 Packet 传输,Packet Number 严格递增,没有依赖。但是 Packet 里的 Payload 如果是 Stream 的话,就需要依靠 Stream 的 Offset 来保证应用数据的顺序。如下图所示,发送端先后发送了 Pakcet N 和 Pakcet N+1,Stream 的 Offset 分别是 x 和 x+y。
假设 Packet N 丢失了,发起重传,重传的 Packet Number 是 N+2,但是它的 Stream 的 Offset 依然是 x,这样就算 Packet N + 2 是后到的,依然可以将 Stream x 和 Stream x+y 按照顺序组织起来,交给应用程序处理。
更大的选择性确认
在 TCP 中,当数据包(Segment)丢失时,接收方不能简单地只回复一个确认号。因为它需要告诉发送方:“我收到了中间断开的那些数据包,请只重传丢失的那个。” TCP 通过 SACK 选项来解决这个问题。
- SACK Block:SACK 选项包含多个“块”(Block),每个块描述了一段已经收到的、但不是按序到达的数据范围。
- 头部限制:TCP 头部有固定的长度限制。TCP 选项的最大长度只有 40 字节,而每个 SACK 块需要 8 字节来描述一个范围(起始和结束)。再加上 SACK 选项本身的头部开销,留给 SACK 块的空间非常有限。
- 最大数量:这导致 TCP 最多只能在头部中携带 3 个 SACK 块。在高丢包率的网络环境下,如果连续丢失了 4 个或更多不连续的数据包,TCP 的 SACK 机制就无法一次性告知发送方所有已收到的数据段,需要等待后续的 ACK 报文。
这种限制使得 TCP 在处理多个不连续丢包时效率低下,需要更多的时间来恢复。
QUIC 协议没有 TCP 的头部限制,它重新设计了自己的确认机制,这就是 ACK Frame。
- ACK Frame 的灵活性:QUIC 的 ACK Frame 是一种单独的帧类型,它可以根据需要动态地调整大小。这意味着它能够承载比 TCP SACK 更多的 ACK 块。
- 更多的 ACK Block:QUIC 的 ACK Frame 可以同时提供 256 个 ACK Block,这个数量远超 TCP 的 3 个。
- 高效的数据恢复:当网络中出现多个不连续的丢包时,QUIC 接收方可以一次性将所有已收到的数据范围告知发送方。发送方收到这个 ACK Frame 后,可以精确地、一次性地重传所有丢失的数据包。
这种设计使得 QUIC 在不稳定的网络环境下,能加快网络恢复速度, 减少重传量和延迟, 比 TCP 拥有更强的健壮性和更高的性能。
不允许 Reneging
在网络协议中,Reneging 指的是接收方在已经通过 ACK 或 SACK 机制向发送方确认收到某个数据包后,又在稍后丢弃了该数据包。这种情况通常发生在接收方的缓冲区或内存资源不足时。
TCP 协议允许这种行为,但并不鼓励。这是因为 TCP 头部空间有限,SACK 块数量少,如果接收方丢弃了数据,发送方会因为收不到这个数据段的后续 ACK,而不得不再次重传,这会带来混乱。
Reneging 对数据传输会造成严重的干扰和效率下降:
- 干扰重传机制:发送方收到 SACK 确认后,会认为这部分数据已经安全到达,不会再重传。但如果接收方事后丢弃了,发送方就无法得知,这会导致数据丢失,需要更复杂的机制(如超时重传)来恢复,浪费了时间和带宽。
- 降低可预测性:发送方无法信任接收方的确认,这使得整个可靠传输机制变得不可靠和不可预测。
为了避免这些问题,QUIC 协议在设计时就明确禁止了 Reneging 行为
改进的拥塞控制
TCP 的拥塞控制实际上包含了四个算法:慢启动,拥塞避免,快速重传,快速恢复。
QUIC 协议当前默认使用了 TCP 协议的 Cubic 拥塞控制算法,同时也支持 CubicBytes, Reno, RenoBytes, BBR, PCC 等拥塞控制算法。(拥塞算法可参考 Google BBR拥塞控制算法原理)
从拥塞算法本身来看,QUIC 只是按照 TCP 协议重新实现了一遍,那么 QUIC 协议到底改进在哪些方面呢?主要有如下几点:
可插拔
能够非常灵活地生效,变更和停止。体现在如下方面:
- 应用程序层面就能实现不同的拥塞控制算法,不需要操作系统,不需要内核支持。这是一个飞跃,因为传统的 TCP 拥塞控制,必须要端到端的网络协议栈支持,才能实现控制效果。而内核和操作系统的部署成本非常高,升级周期很长,这在产品快速迭代,网络爆炸式增长的今天,显然有点满足不了需求。
- 即使是单个应用程序的不同连接也能支持配置不同的拥塞控制。就算是一台服务器,接入的用户网络环境也千差万别,结合大数据及人工智能处理,我们能为各个用户提供不同的但又更加精准更加有效的拥塞控制。比如 BBR 适合,Cubic 适合。
- 应用程序不需要停机和升级就能实现拥塞控制的变更,我们在服务端只需要修改一下配置,reload 一下,完全不需要停止服务就能实现拥塞控制的切换。
QUIC 的拥塞控制之所以更优,主要得益于以下几点:
- 解决了 TCP 的队头阻塞:由于每个 QUIC 流都有独立的拥塞状态和拥塞窗口,一个流的丢包不会导致整个连接的拥塞窗口变小,从而不会影响其他流的传输。
- 更好的性能:在移动网络等不稳定的环境中,QUIC 可以更快速、更精确地识别网络拥塞,并采用更合适的算法来应对,从而提高传输效率。
- 更强的健壮性:当网络环境发生变化(如从 Wi-Fi 切换到蜂窝网络),QUIC 的拥塞状态可以平滑地迁移,而无需重新经历 TCP 的慢启动,这使得网络体验更加流畅。
总而言之,QUIC 通过将拥塞控制从僵化的内核中解放出来,并结合其对流的独立管理能力,提供了比 TCP 更灵活、更高效、更具适应性的拥塞控制机制。
集成TLS
QUIC 集成 TLS 的加密功能是其设计中的一个核心创新点,它与传统 TCP 协议将 TLS 作为附加层的方式截然不同。这种一体化的设计是实现快速连接建立和提高安全性的关键。
在 TCP/IP 协议栈中,TLS 位于应用层和传输层之间, 这种分离的设计使得 TCP 和 TLS 的握手是串行进行的,导致了额外的网络往返时间(RTT)开销。
将 TLS 握手直接嵌入到 QUIC 协议的握手过程中。QUIC 的握手过程同时完成了以下任务:
- 连接建立:客户端和服务器协商连接 ID 等 QUIC 连接参数。
- 密钥交换:客户端和服务器交换加密密钥。
- 身份认证:服务器向客户端发送证书进行身份验证。
这个过程主要通过 QUIC 包中的 CRYPTO 帧来完成。
关键步骤
- 客户端:客户端在建立 QUIC 连接的第一个数据包中,就会发送一个
CRYPTO帧。这个帧包含了 TLS 握手所需的ClientHello消息。 - 服务器:服务器收到这个数据包后,会解析出
ClientHello,并立即回复一个CRYPTO帧,其中包含了ServerHello、服务器证书等信息。 - 客户端:客户端收到服务器的
CRYPTO帧后,会验证证书,然后就可以计算出会话密钥,并开始发送加密的应用数据。
这种集成设计使得 QUIC 能够从协议层面强制所有数据都进行加密,并大大减少了连接建立的延迟,为 HTTP/3 带来了显著的性能提升。
没有队头阻塞的多路复用
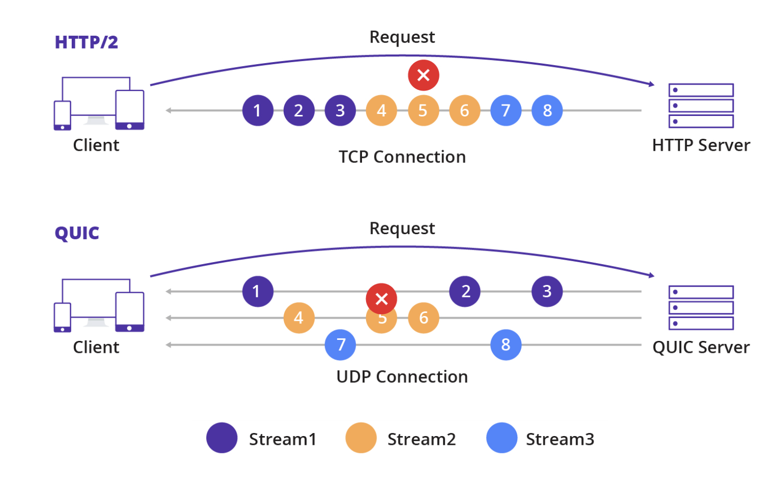
这个机制主要依赖于以下2个关键特性:
流的独立性(Independent Streams)
这是 QUIC 解决队头阻塞问题的根本。在 QUIC 协议中,每个流都被视为一个完全独立的实体。
- TCP/HTTP/2:所有 HTTP/2 流都共享一个单一的 TCP 连接。这意味着,所有流的数据包都被混杂在一个字节流中,由 TCP 按顺序交付。如果中间有一个数据包丢失,TCP 会暂停整个连接的交付,导致所有流都受到影响。
- QUIC/HTTP/3:QUIC 协议将每个流都设置为独立的,拥有自己的流 ID 和序号空间。如果一个流(例如流 A)的数据包丢失,QUIC 协议只会在这个流内部进行处理(例如请求重传),而不会影响同一连接上的其他流(例如流 B 和流 C)。
这就像在一个多车道的高速公路上,每辆车(数据流)都在自己的车道上行驶,一辆车出了事故(丢包)只会影响它自己的车道,而不会堵塞所有车道。
传输单位:基于 UDP 的包(Packet)和帧(Frame)
QUIC 运行在无连接的 UDP 协议之上,这使得它摆脱了 TCP 严格的字节流模式。
- QUIC 包(Packet):QUIC 将所有数据都封装在一个个独立的 UDP 包中。这些包可以乱序到达,由 QUIC 协议在接收端进行管理。
- QUIC 帧(Frame):一个 QUIC 包内部可以包含多个帧。每个帧都带有流 ID。不同流的帧可以被打包到同一个 QUIC 包中进行传输。
这种设计使得 QUIC 可以灵活地将不同流的数据交错发送,而无需担心底层协议的有序性限制。
结合以上两个特性,QUIC 的无队头阻塞多路复用实现过程如下:
发送方:当客户端需要发送多个请求时,它会为每个请求创建一个独立的 QUIC 流(例如,流 1、流 3)。然后,QUIC 协议会将属于不同流的帧打包在同一个或不同的 UDP 包中,并交错地发送出去。
例如,发送方可能先发送流 1 的部分数据,接着发送流 3 的部分数据,再发送流 1 的剩余数据。
传输:这些 UDP 包在网络中传输,它们可能以乱序到达接收方。
接收方:接收方收到这些 UDP 包后:
- 它会根据每个包头部的 Connection ID 将它们识别为同一个 QUIC 连接的数据。
- 然后,它会打开包,并根据每个帧的流 ID 将它们分配给各自的流。
- 如果流 1 的某个帧丢失,QUIC 会在流 1 内部暂停数据交付,并请求重传。
- 但同时,QUIC 会继续处理并交付流 3 的所有数据,因为流 3 的数据与流 1 是完全独立的,没有队头阻塞的依赖关系。
通过这种方式,QUIC 巧妙地将“阻塞”的范围从整个连接缩小到了单个流,从而从根本上解决了 HTTP/2 无法克服的 TCP 队头阻塞问题。
QUIC 使用多路复用为每个 HTTP 请求创建流来传输, 这在某种程度上是否类似于 HTTP 1.1 中使用多个TCP发送请求的优化手段,在不考虑TCP的连接建立开销下,这两种方法的性能差距有多大?
在不考虑 TCP 连接建立开销的情况下,QUIC 使用多路复用流与 HTTP/1.1 使用多个 TCP 连接来发送请求,在理想的、无丢包网络环境下,两者的性能差距会变得非常小。因为在这种理想条件下,它们都能实现请求的并行传输,瓶颈更多在于服务器处理能力和网络带宽。
然而,在真实世界中,只要考虑到丢包,两者之间就会出现巨大的性能鸿沟。
- HTTP/1.1 的多个 TCP 连接: 如果一个 TCP 连接上的数据包丢失,这个连接会进入重传等待,导致该连接上的所有请求都暂停。但其他 TCP 连接是独立的,它们会继续正常工作。这种方法在一定程度上是有效的,因为它将丢包的影响隔离到了单个连接。但它依赖于开启多个连接,而每个连接都有自己的 TCP 慢启动和拥塞窗口,这会带来额外的开销。
- QUIC 的多路复用流: QUIC 将所有流都放在一个 QUIC 连接上, 如果一个流的数据包丢失,QUIC 只会暂停这个流的数据交付,而不会影响同一连接上的其他流。其他流可以继续并行地传输,不受影响
但在真实网络环境下,QUIC 的这种设计比 HTTP/1.1 优越得多:
- 更强的健壮性:HTTP/1.1 依赖于多个独立的、昂贵的 TCP 连接来隔离丢包。而 QUIC 在一个连接上,就实现了更好的隔离,避免了多连接的开销(如频繁的慢启动)。
- 更高效的资源利用:QUIC 可以更智能地管理单个连接上的带宽,动态地调整每个流的优先级和流量,从而最大限度地提高吞吐量。
- 更快的用户体验:当某个请求的数据包丢失时,QUIC 能够继续交付其他请求的数据,HTTP/1.1 的多TCP由于TCP连接数限制, 总是可能会有请求会被阻塞, 这意味着用户不会因为一个资源的延迟而等待整个页面加载
在不考虑连接建立开销的理想条件下,两者的性能差距不大。但只要将丢包这个现实因素考虑进来,HTTP/1.1 的并行方法会因为每个连接的独立拥塞窗口和慢启动而效率低下,而 QUIC 的多路复用能够在一个连接上提供更强的并行能力和更好的容错性,从而在性能上取得显著优势。
头部压缩的队头阻塞
HTTP 2 中除了 TCP 以外, 首部压缩的 HPACK 算法也可能导致队头阻塞
- HTTP/2: HTTP/2 使用 HPACK 算法压缩头部。虽然 HPACK 本身很高效,但它有一个缺陷:为了解压头部,接收方必须按顺序接收所有头部压缩的帧。如果一个头部压缩帧丢失了,即使其他流的头部帧已经到达,它们也无法被解压,从而导致头部压缩的队头阻塞。
- HTTP/3: HTTP/3 使用 QPACK 算法来解决这个问题。QPACK 允许在不影响其他流的情况下,独立地处理头部压缩。它将头部编码分为两个部分:一个引用静态/动态字典的流和一个包含实际数据的流。这使得即使一个流的头部数据丢失,也不会阻塞其他流的头部解码,从而避免了头部压缩带来的队头阻塞。
流控制
QUIC 的流量控制类似 HTTP2,即在 Connection 和 Stream 级别提供了两种流量控制。为什么需要两类流量控制呢?主要是因为 QUIC 支持多路复用。
- Stream 就是一条
HTTP 请求-响应对。 - Connection 指一个客户端与一个服务器之间的整个通信会话。多路复用意味着在一条 Connetion 上会同时存在多条 Stream。既需要对单个 Stream 进行控制,又需要针对所有 Stream 进行总体控制。
QUIC 实现流量控制的原理比较简单:
通过 window_update 帧告诉对端自己可以接收的字节数,这样发送方就不会发送超过这个数量的数据。
通过 BlockFrame 告诉对端由于流量控制被阻塞了,无法发送数据。
QUIC 的流量控制和 TCP 有点区别,TCP 为了保证可靠性,窗口左边沿向右滑动时的长度取决于已经确认的字节数。如果中间出现丢包,就算接收到了更大序号的 Segment,窗口也无法超过这个序列号。
但 QUIC 不同,就算此前有些 packet 没有接收到,它的滑动只取决于接收到的最大偏移字节数。
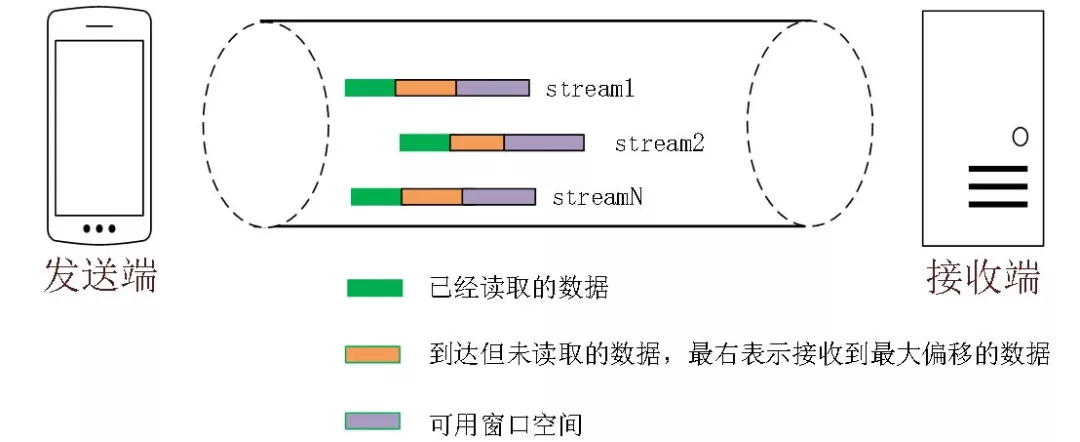
针对 Stream:
$可用窗口 = 最大窗口数 - 接受到的最大偏移数$
针对 Connection:
$ 可用窗口 = Stream1可用窗口 + Stream2可用窗口 + …… + StreamN可用窗口 $
相比于 TCP 只有连接级别的流量控制,QUIC 的双层机制提供了更灵活、更高效的资源管理:
- 更精细的控制:QUIC 可以根据每个流的特点(例如优先级)来分配不同的流量窗口,实现更智能的资源分配。
- 防止饥饿:流级别控制确保了即使有一个流在高速传输,其他流依然有自己的独立窗口,能够顺利传输数据,避免了“饿死”现象。
- 整体保护:连接级别的控制作为最后的屏障,防止发送方在任何情况下都发送过多的数据,确保了接收方的稳定运行。
前向纠错
HTTP/3 中的前向纠错(Forward Error Correction, FEC)是一种可选的机制,它可以减少因数据包丢失而导致的延迟,从而进一步提高传输效率。
前向纠错的原理 在传统的网络协议中,如果数据包丢失,发送方必须重新发送这个丢失的数据包。这个过程需要一个完整的网络往返时间(RTT)来确认丢失并进行重传。
前向纠错改变了这个模式。它的核心思想是:发送方在发送原始数据包的同时,也发送一些额外的、冗余的“纠错包”。这些纠错包是通过对原始数据进行某种算法运算得到的。
当接收方收到数据包时:
- 如果所有原始数据包都完整到达,接收方直接处理它们,并丢弃冗余的纠错包。
- 如果某个原始数据包丢失了,接收方可以利用收到的其他原始数据包和冗余的纠错包,通过计算直接恢复出丢失的数据,而无需等待发送方的重传。
QUIC 协议(HTTP/3 的底层)允许在流或包级别实现前向纠错。
- 工作方式:发送方可以将多个数据包(例如,数据包 A、B 和 C)分组,并为这个组生成一个额外的纠错包 X。这个纠错包 X 是由 A、B、C 三个包共同计算得出的。
- 数据恢复:如果数据包 A 丢失了,接收方可以利用收到的 B、C 和 X 来恢复出 A 的数据。整个过程不需要发送方介入,也不需要额外的 RTT。
但它没有规定具体的算法。大多数早期的实现都采用了简单的异或运算作为基础
用户空间实现
什么是用户空间?
内核空间和用户空间是现代操作系统中两个最核心、最基础的概念,它们是操作系统为了保护自身安全和稳定而划分出的两个不同的内存区域和执行环境。
- 内核空间: 是操作系统内核运行的地方,是系统的核心区域。它拥有最高的权限,可以直接访问计算机的所有硬件资源,包括 CPU、内存、硬盘和各种设备。
- 用户空间: 是所有应用程序(比如浏览器、游戏、文本编辑器)运行的地方。
这种隔离机制确保了即使一个应用程序崩溃或存在恶意行为,它也只能破坏自己所处的用户空间,而不会影响到操作系统内核,从而保证了整个系统的安全和稳定
用户空间实现(User-space implementation)指的是将一个协议栈(如 QUIC)的代码运行在操作系统的应用程序层面,而不是像传统协议(如 TCP)那样集成在操作系统的内核中
用户空间和内核空间切换的上下文切换(Context Switch)会带来显著的性能开销。这是因为这种切换不仅仅是简单地改变执行位置,它还涉及到保存和加载大量的状态信息
在网络协议中,性能至关重要。传统的 TCP 协议栈在内核中实现,而应用程序在用户空间。每次应用程序需要发送或接收数据时,它都必须通过系统调用从用户空间切换到内核空间。
QUIC 选择在用户空间实现,是为了解决传统 TCP 协议因其内核实现所带来的僵化和部署困难问题。主要有以下几个核心原因:
- 灵活快速的迭代和部署
- 内核的僵化:TCP 协议代码集成在操作系统内核中,其更新和部署非常缓慢。例如,如果你想给 TCP 引入一个新的拥塞控制算法,需要等待操作系统发布新的版本,这可能需要数年时间。
- QUIC 的灵活性:QUIC 协议栈运行在应用程序代码中,开发者可以像更新普通应用一样,快速地更新和部署新的 QUIC 协议版本。这使得 QUIC 能够快速修复漏洞、引入新的特性(如更先进的拥塞控制算法)并适应最新的网络环境。
- 避免操作系统和设备厂商的限制
- 传统模式:TCP 的性能和特性受制于操作系统厂商(如微软、苹果)和设备厂商。如果一个新特性没有被这些厂商支持并集成到系统中,就无法被广泛应用。
- QUIC 的独立性:QUIC 协议是独立于操作系统的。只要你的应用程序支持 QUIC,它就能在任何操作系统上使用,而无需等待系统更新。这大大降低了新协议部署的门槛,加快了其在全球范围内的普及。
- 更好的性能与控制
- 避免内核-用户空间切换:传统 TCP 传输数据时,需要在内核空间和用户空间之间进行多次数据拷贝和上下文切换,这会带来额外的性能开销。QUIC 在用户空间实现,可以减少这种切换,提高效率。
- 更精细的控制:应用程序可以直接控制 QUIC 协议栈的行为,例如,可以根据应用需求动态调整拥塞控制算法、优先级和流管理策略,实现更细粒度的性能优化。
QUIC 选择用户空间实现,是其设计哲学“实用主义”的体现。它通过牺牲部分与操作系统的深度集成,换取了巨大的灵活性、可控性和快速迭代能力,从而能够更好地适应现代复杂多变的互联网环境。
HTTP 3 (QUIC) 的挑战
QUIC 的 0-RTT 成功率不高
导致 0-RTT 成功率不高的原因一般有如下几个:
服务端一般都是集群,对于客户端来说,处理请求的服务端是不固定的,新的请求到来时,如果当前 client 没有请求过该服务器,则服务器上没有相关会话信息,会把该请求当做一个新的连接来处理,重新走 1-RTT。
针对此种情况,我们可以考虑集群中所有的服务器使用相同的 ticket 文件。
客户端 IP 不是固定的,在发生连接迁移时,服务端下发的 token 融合了客户端的 IP,这个 IP 变化了的话,携带 token 服务端校验不过,0-RTT 会失败。
针对这个问题,我们可以考虑采用下图所示的方法,使用设备信息或者 APP 信息来生成 token,唯一标识一个客户端。
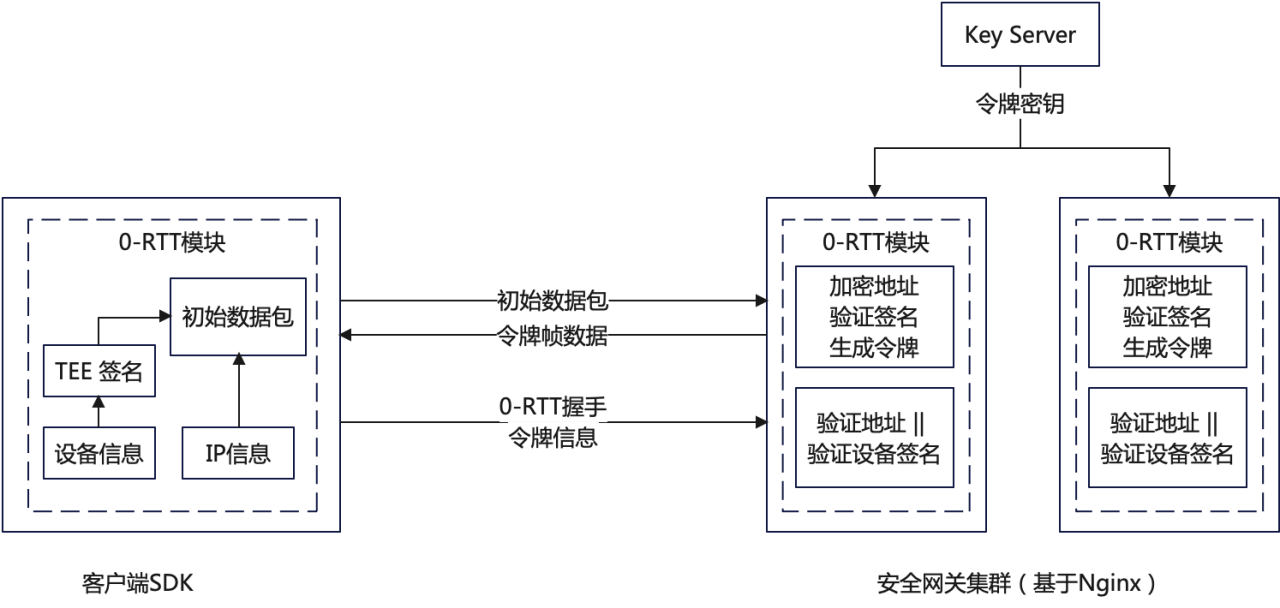
Session Ticket 过期时间默认是 2 天,超过 2 天后就会导致 0-RTT 失败,然后降级走 1-RTT。可以考虑增长过期时间。
实现连接迁移并不容易
连接迁移的实现,不可避开的两个问题:一个是四层负载均衡器对连接迁移的影响,一个是七层负载均衡器对连接迁移的影响。
四层负载均衡器的影响:LVS、DPVS 等四层负载均衡工具基于四元组进行转发,当连接迁移发生时,四元组会发生变化,该组件就会把同一个请求的数据包发送到不同的后端服务器上,导致连接迁移失败;
七层负载均衡器的影响(QUIC 服务器多核的影响):由于多核的影响,一般服务器会有多个 QUIC 服务端进程,每个进程负载处理不同的连接。内核收到数据包后,会根据二元组(源 IP、源 port)选择已经存在的连接,并把数据包交给对应的 socket。在连接迁移发生时,源地址发生改变,可能会让接下来的数据包去到不同的进程,影响 socket 数据的接收。
如何解决以上两个问题?DPVS 要想支持 QUIC 的连接迁移,就不能再以四元组进行转发,需要以连接 ID 进行转发,需要建立 连接 ID 与对应的后端服务器的对应关系;
QUIC 服务器也是一样的,内核就不能用四元组来进行查找 socket,四元组查找不到时,就必须使用连接 ID 进行查找 socket。但是内核代码又不能去修改(不可能去更新所有服务器的内核版本),那么我们可以使用 eBPF 的方法进行解决。如下图所示:
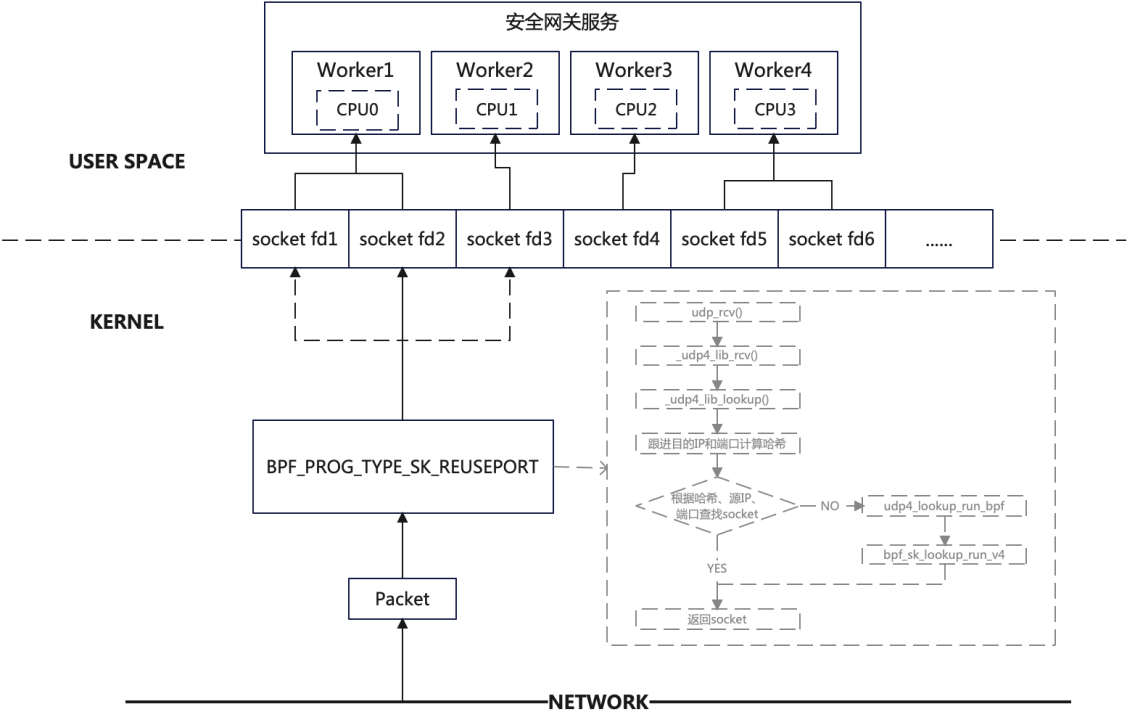
eBPF (extended Berkeley Packet Filter) 允许开发者在不修改内核源代码的情况下,将自定义的程序动态加载到内核中运行。这样,就可以编写一个 eBPF 程序,让内核在四元组查找失败时,能够尝试使用 Connection ID 来查找正确的 Socket,并将数据包交给相应的 QUIC 服务端进程。
UDP 被限速或禁闭
QUIC基于UDP协议,而运营商或网络设备(如防火墙、NAT网关)在某些情况下会优先处理和优化TCP流量,并对UDP流量进行QoS(服务质量)限制或丢弃,导致UDP协议的效率降低,从而影响QUIC的速度。
- 基础协议的限制: QUIC协议在传输层使用了UDP,而不是像传统的HTTP一样基于TCP。虽然QUIC在设计上旨在提高效率和可靠性,但在网络基础设施层面,UDP协议的普遍性不如TCP,运营商通常对TCP协议有更完善的支持和优化。
- 运营商的QoS策略: 一些运营商的网络设备会配置QoS策略,对UDP流量进行优先级排序或限速。这可能导致带宽紧张时,QUIC(作为UDP流量)更容易受到限制。
很多企业、运营商和组织对53端口(DNS)以外的UDP流量进行拦截或者限流,因为这些流量近来常被滥用于攻击。特别是一些现有的UDP协议和实现易受放大攻击(amplification attack)威胁,攻击者可以控制无辜的主机向受害者投放发送大量的流量。
网络设备的兼容性问题:
- 防火墙:一些防火墙或网络安全设备可能没有对QUIC或其使用的UDP端口进行充分的支持,有时会直接丢弃UDP数据包。
- NAT网关:某些网络地址转换(NAT)网关对UDP连接的会话生存时间设置得较短,这也会影响QUIC的稳定性。
非标准端口的干扰:
尽管QUIC默认使用UDP的443端口,但如果一些实现使用了其他端口,也可能引起网络设备的误判和拦截,导致限速或封锁。
因此,虽然QUIC协议自身设计上具备速度和稳定性的优势,但在一些对UDP协议支持不够友好或限制较多的网络环境中,就容易受到运营商的限速影响。
QUIC 对 CPU 消耗大
QUIC 的 CPU 开销通常比 TCP 更大,但这是一种为了换取更好的网络性能(尤其是低延迟和高健壮性)而进行的权衡。这种开销主要体现在以下几个方面:
强制加密 (Mandatory Encryption)
这是 QUIC 带来额外 CPU 开销的最主要原因。
QUIC:QUIC 协议要求所有数据都必须经过加密。这意味着每一个数据包在发送前都需要进行加密运算,在接收后都需要进行解密运算。尽管现代 CPU 有硬件加速来处理 AES-GCM 等加密算法,但这个计算过程是无法被消除的。
TCP:TCP 本身不加密。加密是作为 TLS 层附加在 TCP 之上的。对于那些不使用 HTTPS 的应用(例如 FTP 或 Telnet),TCP 的 CPU 开销几乎为零,而 QUIC 在任何情况下都有加密开销。
用户空间处理 (User-space Processing)
QUIC 协议栈运行在用户空间,而 TCP 协议栈集成在操作系统内核中。
QUIC:QUIC 必须在应用程序的 CPU 上执行所有协议逻辑,包括可靠性、拥塞控制和多路复用。虽然这避免了频繁的内核-用户空间上下文切换开销,但协议处理本身的 CPU 周期可能比高度优化的内核代码要高。
TCP:TCP 协议栈由内核处理,其代码经过了多年的高度优化,并且可以利用操作系统的底层特性。这种内核实现通常非常高效,每字节数据的处理成本极低。
复杂的包和流管理 (Complex Packet & Stream Management)
QUIC 的设计更加复杂,需要更多的 CPU 周期来处理和管理。
QUIC:QUIC 包内部是帧,需要额外的 CPU 周期来解析、封装和重组。此外,QUIC 需要在每个流上独立管理序列号、流量控制窗口和拥塞状态,这都增加了协议栈的复杂性和计算量。
TCP:TCP 的头部相对简单,内核对其解析和处理非常高效。所有数据都被视为一个单一的字节流,管理起来相对简单。并且内核知道 TCP 连接的状态,不用为每一个数据包去做诸如查找目的路由、防火墙规则等操作,只需要在 tcp 连接建立的时候做一次即可,然而 QUIC 不行;
QUIC 的 CPU 开销确实更大,尤其体现在强制加密和用户空间处理上。但这种开销是可预测的、可控的。通过它,QUIC 成功避免了 TCP 在不稳定网络环境下所造成的不可预测的、巨大的延迟和等待开销。